Your curated collection of saved posts and media
Early tickets cover variables, functions, types, operators, and control flow. Through increasingly complex tickets, you'll also learn Mojo's ownership and metaprogramming. Every problem runs your code through the Mojo compiler so you can learn from the authentic error messages.
Introducing Devin Security Swarm A more cost effective and accurate way to find security vulnerabilities in complex codebases, based on a new architecture: Agentic MapReduce.
3D scene reconstruction works great until the camera never sees part of the scene. ArtiFixer from NVIDIA Research is an open autoregressive model that fills in the missing geometry that other methods leave blank. #SIGGRAPH2026 paper, code + demo: https://t.co/D9PX2OzbZf https://t.co/AGQicvVKkW
before model distillation was an attack vector. it was. pretty handy way of improving model performance on a task you care about. especially if you want to take small, local, or cheap model and improve it on a tasks typically reserved to large models. in the next live stream, we're going to break down knowledge distillation in post-training and show you how to implement it. going out next week: July 7th 8am PST, 5pm CEST live on: @huggingface X, YT, LI

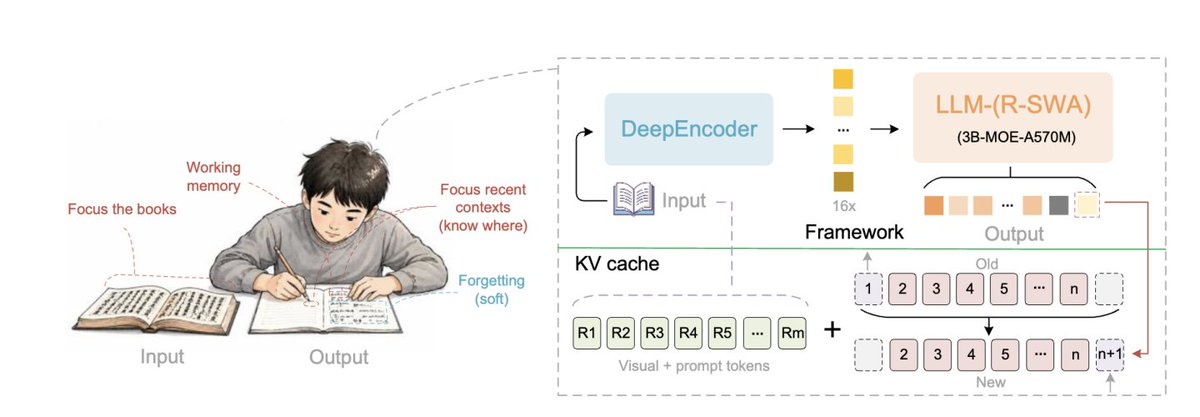
We’re open-sourcing Unlimited OCR — built to read long documents in one pass. With 3B total parameters and only 500M activated, Unlimited OCR sets new end-to-end SOTA results on OmniDocBench v1.5 and v1.6. The key innovation is Reference Sliding Window Attention (R-SWA), inspired by how humans transcribe books: keeping the source, recent context, and next words in focus, while softly forgetting what’s no longer needed. With constant KV Cache size and lower attention cost, Unlimited OCR can transcribe 40+ pages in a single forward pass — without losing context or slowing down. Explore the model👇: --GitHub: https://t.co/5ZJBsEldKd --Hugging Face: https://t.co/4FKFr9EfOu

📢WorldMesh is accepted to #ECCV2026, and we're releasing the code today! 🎉 Led by @mschneider456: navigable, multi-room 3D scenes from a text prompt, with a mesh scaffold conditioning image diffusion for global consistency + photorealistic detail 👇 https://t.co/8fXCl2flIu https://t.co/Z1HkoO3s37
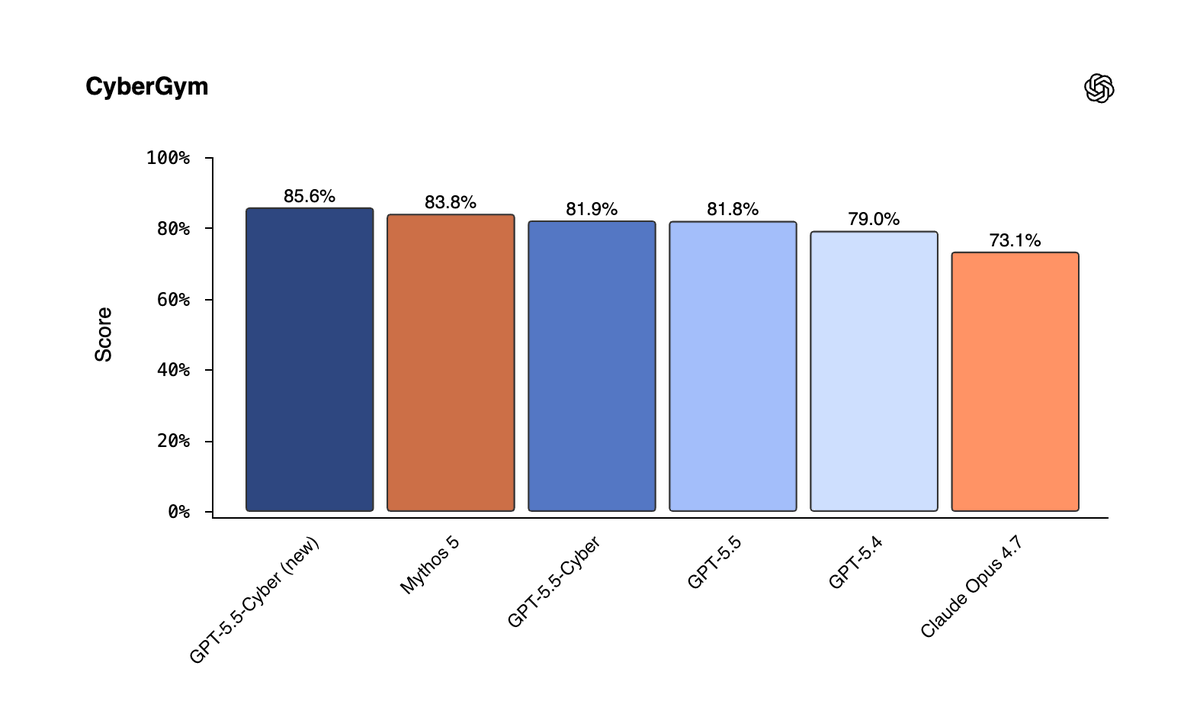
GPT-5.5-Cyber is our most capable cyber model yet, designed for advanced, authorized defensive work: tracing vulnerable code, validating issues, developing patches, and preparing evidence for human review. https://t.co/KcDoGGD2tx
1-bit GLM-5.2 GGUF vs. Claude 4.8 Opus vs. GPT-5.5 We gave 3 models the same prompt and compared one-shot outputs. The 1-bit GLM-5.2 GGUF ran locally on a Mac Studio M3 Ultra with 256GB RAM at ~21.6 tok/s. Which output do you like best? GGUF: https://t.co/BMkxswdj5N https://t.co/UoXsCSh4Gn
GLM-5.2 can now be run locally!🔥 The 2-bit model retains ~82% accuracy after we shrunk it from 1.51TB to 238GB (-84% size). Run on a 256GB Mac or RAM/VRAM setups. GLM-5.2 is the strongest open model to date. Guide: https://t.co/bI7FeeKHDd GGUF: https://t.co/BMkxswdj5N https:/

@unixpickle Are you still playing with text-to-CAD? The last few times I've tried GPT 5.5 has made almost-useable (and easily salvageable) bits for me in OpenSCAD.
Accepted to #ECCV2026! 🎉 We've also released the code, it should work like a charm. If it doesn't, feel free to poke @roodiiiiiiiii 😄 https://t.co/t5M0J7S1GR
Group3D MLLM-Driven Semantic Grouping for Open-Vocabulary 3D Object Detection paper: https://t.co/8NVynfAm2u https://t.co/RzkYdEKhRk