Your curated collection of saved posts and media
Early tickets cover variables, functions, types, operators, and control flow. Through increasingly complex tickets, you'll also learn Mojo's ownership and metaprogramming. Every problem runs your code through the Mojo compiler so you can learn from the authentic error messages.
Today's YouTube video is a longer look at MoA in Hermes Agent, trying to answer some of the common questions: How does using MoA impact cost, speed, and quality? I created an open weights MoA using GLM-5.2, Kimi K2.6 and Minimax M3 to find out, then made a three-headed Grok with GPT-5.5 as the aggregator to see if that added some much-needed style to the GPT model. Check it out! https://t.co/lQMfbuI1Ix
Nous Research just dropped MOA (Mixture of Agents) presets inside Hermes Agent. I made a quick video showing how to set it up and create your own MOA. The idea: mix multiple models to get capabilities beyond any single model you can use right now. How it works: Normally Hermes
before model distillation was an attack vector. it was. pretty handy way of improving model performance on a task you care about. especially if you want to take small, local, or cheap model and improve it on a tasks typically reserved to large models. in the next live stream, we're going to break down knowledge distillation in post-training and show you how to implement it. going out next week: July 7th 8am PST, 5pm CEST live on: @huggingface X, YT, LI

We’re open-sourcing Unlimited OCR — built to read long documents in one pass. With 3B total parameters and only 500M activated, Unlimited OCR sets new end-to-end SOTA results on OmniDocBench v1.5 and v1.6. The key innovation is Reference Sliding Window Attention (R-SWA), inspired by how humans transcribe books: keeping the source, recent context, and next words in focus, while softly forgetting what’s no longer needed. With constant KV Cache size and lower attention cost, Unlimited OCR can transcribe 40+ pages in a single forward pass — without losing context or slowing down. Explore the model👇: --GitHub: https://t.co/5ZJBsEldKd --Hugging Face: https://t.co/4FKFr9EfOu
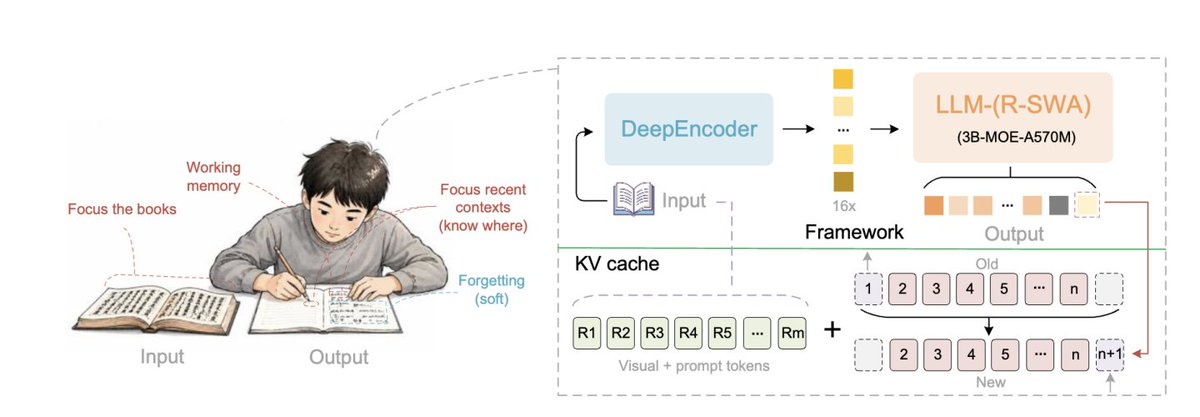

introducing https://t.co/oLxCg1Fe68, a reference agent template. built on eve, it's a great starting point for building your own agent, whether for support, incident response, deep research, or otherwise. includes Next.js web chat, Slack bot, BetterAuth, Neon, and Notion, Linear, and Sentry MCPs.
HalluHard update: We’ve added GLM-5.2, using adaptive thinking with maximum reasoning effort, to our leaderboard. Despite its impressive performance on other benchmarks, GLM-5.2 still hallucinates frequently on our challenging multiturn benchmark. https://t.co/xbppFeo7Pd
That's right, an open, MIT-licensed model beating GPT-5.5 (xhigh) on real-world agentic work! 🔥 Available for free on @huggingface for anyone to build on top off https://t.co/9TYnygzmf5
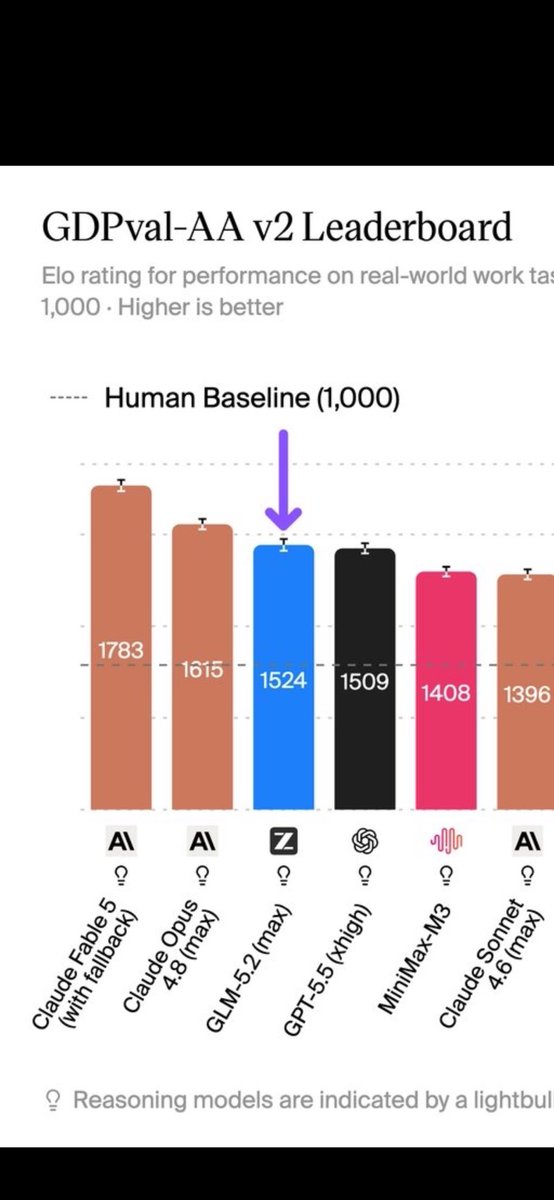
GLM-5.2 leads open weights models and sits at #3 overall on GDPval-AA, a real-world agentic work benchmark GLM-5.2 from @Zai_org scores 1524 Elo on GDPval-AA, which measures performance on real-world, economically valuable knowledge work through long-horizon, multi-turn tasks.
@unixpickle Are you still playing with text-to-CAD? The last few times I've tried GPT 5.5 has made almost-useable (and easily salvageable) bits for me in OpenSCAD.
Didn't have much time to play with this today but I: - Got a peek at a real microfluidics chip+setup - Tested stepper-controlled fluid dispensing - Got my design-to-finished-chip time down to a 20-minute speed run - Made some droplets! The quest continues :) https://t.co/jVikwlfbly


Thanks for running our open-source work on current frontier models “The results are: the most capable models today (GPT-5.5 Pro) did outperform the best models from before (79/100 vs 69/100), but did not improve enough to be considered sufficient for reliable medical use.” Read full text and results below