Your curated collection of saved posts and media
@salomon_diei The basic idea is easy and v0 is a hackathon project. The product here is a lot closer to *it actually works*, for enterprise grade deployments, and after quite a bit of internal experimentation and iteration. It’s kind of hard to describe other than (per the post) it’s writing majority of code, it’s deeply integrated, multiplayer, and it starts to feel like everyone is a manager. So I understand it looks easy to dismiss on quick reading but it’s not some LLM Q&A with RAG over Slack, it’s not even OpenClaw adjacent, it’s a different way of working entirely, for people and teams. I work from Slack now.
Got the model converted to CoreML and working on iOS; will open source soon! https://t.co/6xo8VetVGT
Today, we are releasing Rampart: a 14.7MB machine learning model designed to protect citizens’ privacy by redacting personal information directly in your browser before it gets sent to any server
Easily the biggest unlock for vibe coding 1
describing an aesthetic in a prompt can be tough, so we made a button for it introducing Design Variations instantly generate, explore, and apply beautiful new UI layouts with a single click try it today in AI Studio https://t.co/cVnR4hjJZe https://t.co/JEyuImiWcP
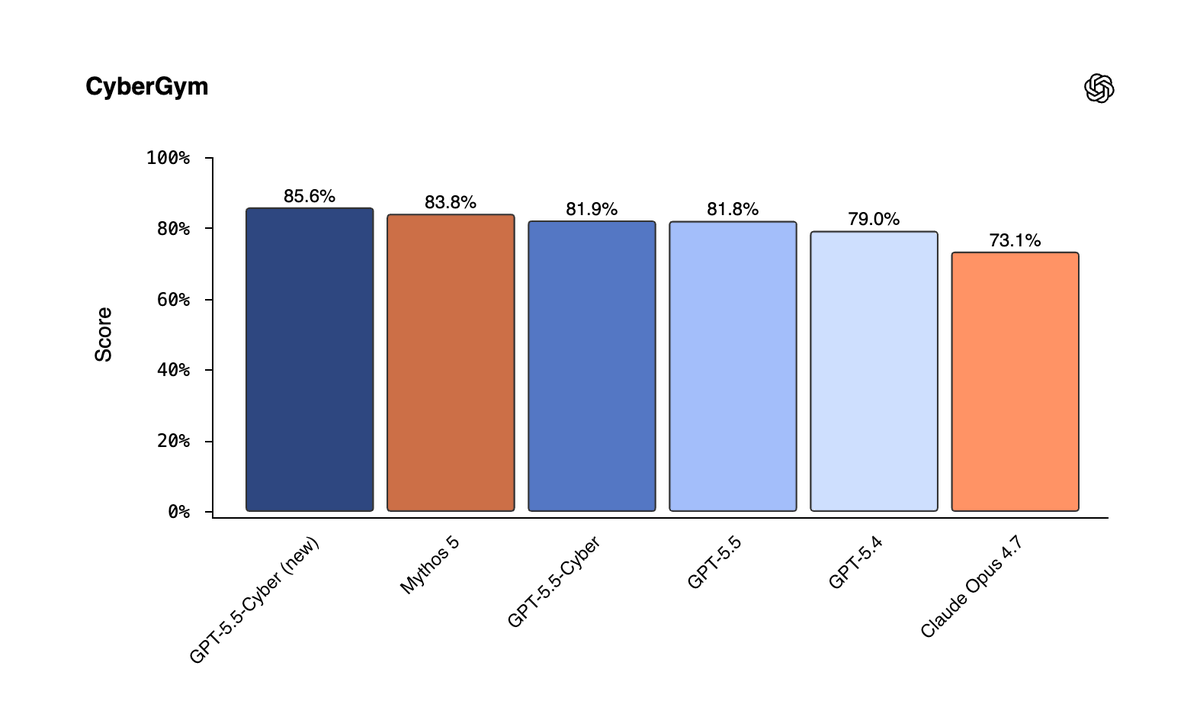
GPT-5.5-Cyber is our most capable cyber model yet, designed for advanced, authorized defensive work: tracing vulnerable code, validating issues, developing patches, and preparing evidence for human review. https://t.co/KcDoGGD2tx
Deeper Instructions, Stronger Generalization: Training on ComplexConstraints Given the chance, a model will reward hack however it can: finding the laziest path that satisfies a grader, whether or not that path reflects what you actually wanted. If the grader can be satisfied by a surface trick, that trick is what the model learns. Most instruction-following benchmarks are full of surface tricks. "Stay under 300 words," "avoid commas", a model can satisfy those by scanning the output text, without understanding the task at all. ComplexConstraints, our frontier instruction-following benchmark, is built so there's no lazy path: its constraints fire only under certain conditions, depend on the outputs of earlier steps, require planning ahead, and are often left unstated. You can't satisfy "don't assign anyone with a religious dietary restriction to pork prep" by pattern-matching. You have to understand who's who and reason through many interdependent requirements at once. We post-trained Qwen3-4B on 1,000 of these tasks, using expert-written rubrics directly as the RL reward. The results: → +15.5pp on the held-out set, reaching parity with a model 60x larger → the gains transferred to two external benchmarks the model never trained on: +8.4pp on Meta's AdvancedIF and +10.1pp on MultiChallenge → the largest gains landed on multi-turn abilities, even though every training example was single-turn Think about that last result. When the only way to score is to actually track many interdependent requirements, the model learns that skill rather than a shortcut, and the skill is the same whether the requirements arrive in one complex prompt or accumulate over nine turns. So it showed up on tasks the model was never trained on. A reward signal is only as good as the thought behind it, and not all rubrics are created the same. Research Blog: https://t.co/bUJPcoNFrX Research Paper: https://t.co/zQxE0TN260
I'm going to try the new @NVIDIAAI Nemotron-3-Nano-30B-A3B and compare it to Qwen 3.6 35B in agentic workflows. https://t.co/z9cnRBOo1c

In their AI CUDA Engineer work they reported results that were not just bugged but obviously impossible. As both Tri Dao and I quickly noticed, they claimed speed ups for real workloads that outperformed the theoretical max of the GPUs. https://t.co/eoYvEtkevJ
A heuristic always worth checking when it comes to compute-efficiency: are they claiming to beat the maximum theoretical FLOPS that the hardware supports? They claim their kernel beats the hardware's theoretical max here by a factor of 30x!

I have been trying Sakana Fugu Ultra-high and, first, it is incredibly slow: my typical coding tests (shaders, interactive scenes) take 30 minutes to run And the results are... fine. It does not match Fable in real use. Its harbor is a good example: https://t.co/xVqulPBsQf
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: https://t.co/hhO6qTawgb 🐡
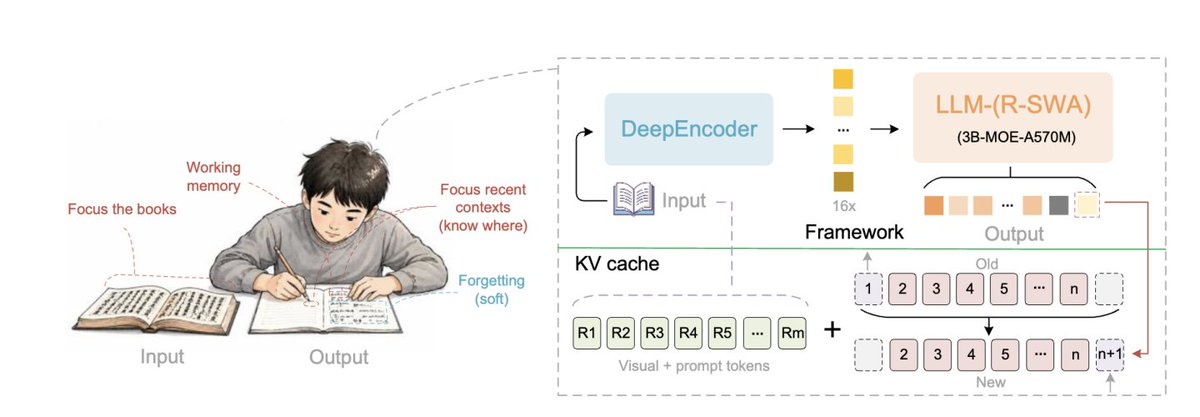
We’re open-sourcing Unlimited OCR — built to read long documents in one pass. With 3B total parameters and only 500M activated, Unlimited OCR sets new end-to-end SOTA results on OmniDocBench v1.5 and v1.6. The key innovation is Reference Sliding Window Attention (R-SWA), inspired by how humans transcribe books: keeping the source, recent context, and next words in focus, while softly forgetting what’s no longer needed. With constant KV Cache size and lower attention cost, Unlimited OCR can transcribe 40+ pages in a single forward pass — without losing context or slowing down. Explore the model👇: --GitHub: https://t.co/5ZJBsEldKd --Hugging Face: https://t.co/4FKFr9EfOu

⚡ Agent Foundations Get started with agent-first development and learn how to build applications using Agent Mode in VS Code. 🔗 https://t.co/ag5zffSLjd https://t.co/VIe4EsmPoi
