Your curated collection of saved posts and media
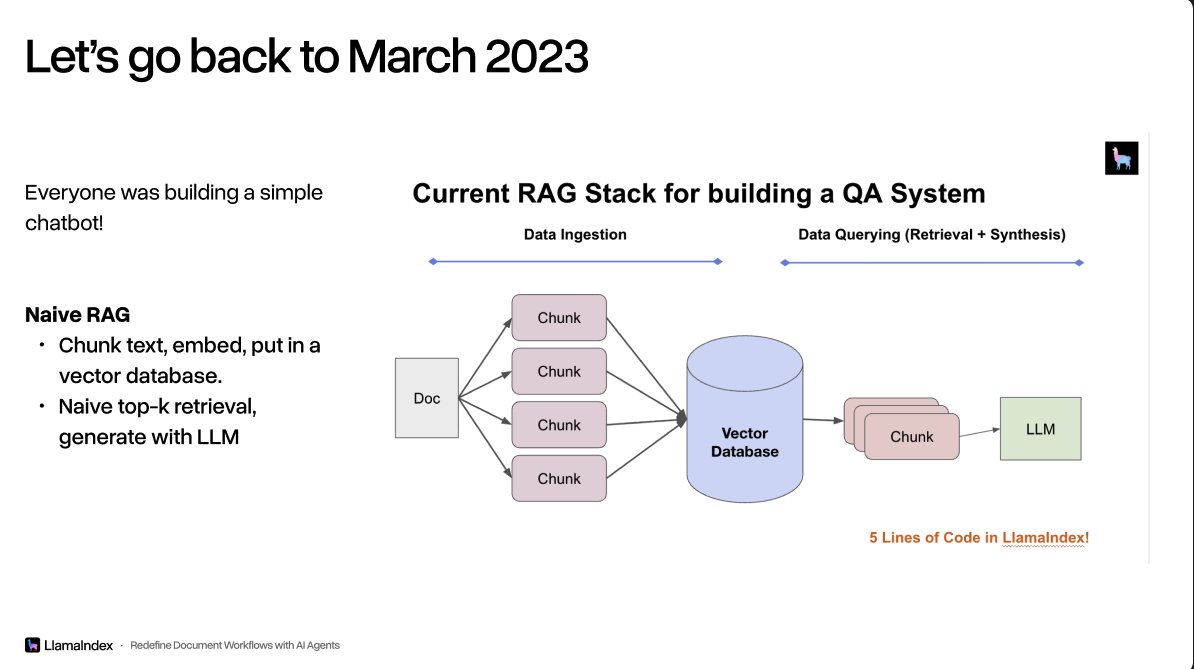
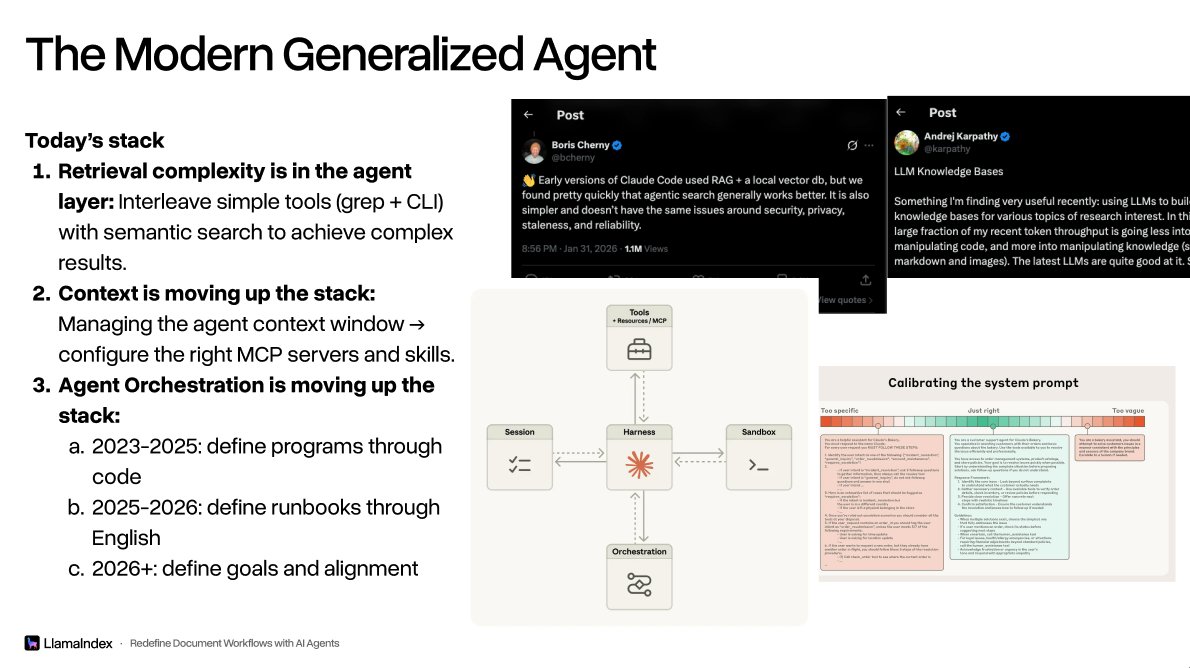
3 years ago I gave a talk at the first @aiDotEngineer conference on "Advanced RAG" techniques in order to work around the limitations of naive RAG. It's insane how much the world has changed since then, and the world has evolved into standardized, higher-level abstractions around agent harnesses and context. Some general patterns: 1. Retrieval complexity can be encoded at the agent layer. This means that you can give relatively simple but performant search tools to an agent (e.g. really fast bm25, vector search), and let the agent reasoning enter the right queries to find the right results. 2. To some extent this is still evolving, but I do think we will increasingly care less about "hacking" the context window and more about deciding what business context is relevant in the first place. 3. The way we build agents has fundamentally changed from defining code, to defining runbooks, to defining goals. Big congrats to @swyx and the entire AI Engineer team for continuing to put out awesome conferences every year.
@salomon_diei The basic idea is easy and v0 is a hackathon project. The product here is a lot closer to *it actually works*, for enterprise grade deployments, and after quite a bit of internal experimentation and iteration. It’s kind of hard to describe other than (per the post) it’s writing majority of code, it’s deeply integrated, multiplayer, and it starts to feel like everyone is a manager. So I understand it looks easy to dismiss on quick reading but it’s not some LLM Q&A with RAG over Slack, it’s not even OpenClaw adjacent, it’s a different way of working entirely, for people and teams. I work from Slack now.
Experiments towards manual sorting - peristaltic pump style jog wheel is a fun interface to use when looking through the microscope at tiny channels :) https://t.co/cELraTj5nc

@unixpickle Are you still playing with text-to-CAD? The last few times I've tried GPT 5.5 has made almost-useable (and easily salvageable) bits for me in OpenSCAD.
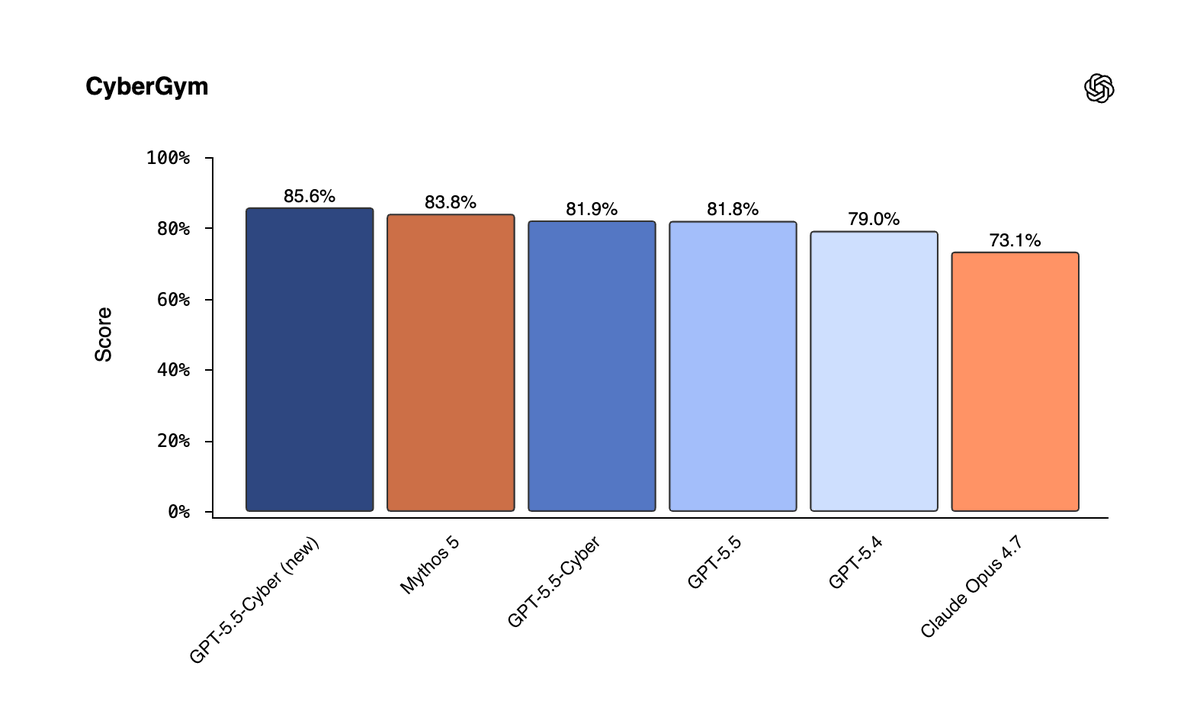
GPT-5.5-Cyber is our most capable cyber model yet, designed for advanced, authorized defensive work: tracing vulnerable code, validating issues, developing patches, and preparing evidence for human review. https://t.co/KcDoGGD2tx
Today's YouTube video is a longer look at MoA in Hermes Agent, trying to answer some of the common questions: How does using MoA impact cost, speed, and quality? I created an open weights MoA using GLM-5.2, Kimi K2.6 and Minimax M3 to find out, then made a three-headed Grok with GPT-5.5 as the aggregator to see if that added some much-needed style to the GPT model. Check it out! https://t.co/lQMfbuI1Ix
Nous Research just dropped MOA (Mixture of Agents) presets inside Hermes Agent. I made a quick video showing how to set it up and create your own MOA. The idea: mix multiple models to get capabilities beyond any single model you can use right now. How it works: Normally Hermes
We’re introducing GeneBench-Pro, a research-level benchmark for a harder kind of AI progress: how well agents can navigate messy biological data, choose the right analysis path, and make judgment calls that real computational research depends on. https://t.co/AsilnnSxnE
I have been trying Sakana Fugu Ultra-high and, first, it is incredibly slow: my typical coding tests (shaders, interactive scenes) take 30 minutes to run And the results are... fine. It does not match Fable in real use. Its harbor is a good example: https://t.co/xVqulPBsQf
Introducing Sakana Fugu: A full multi-agent orchestration system accessible via a single model API. Our ‘Fugu Ultra’ model matches the performance of Fable and Mythos, delivering frontier capability without the risk of export controls. Try it: https://t.co/hhO6qTawgb 🐡
Day 1 of vibecoding https://t.co/n8ff35htEV

@francoisfleuret Moving bits to and from memory. Because of parasitic capacitance+resistance of the wires. The bigger the memory, the longer the wires. The main trick is to organize the memory hierarchically: registers, small on-chip SRAM, caches of various types, and external RAM. It's all because we have to use hardware multiplexing: reusing the same multiply-accumulate unit for multiple parts of the network.