@jerryjliu0
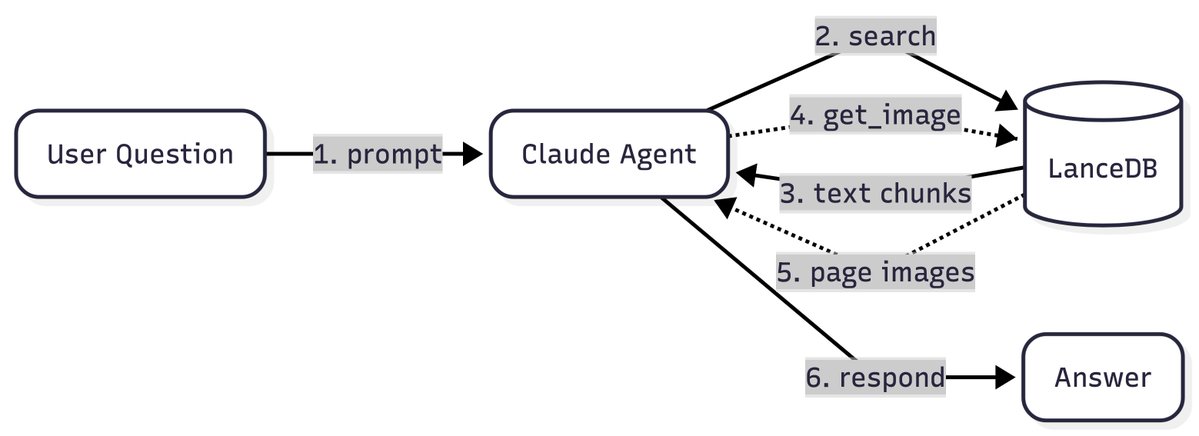
This is a great tutorial (credits @itsclelia + @lancedb) on how to build a practical retrieval pipeline that integrates directly with your agent harness. 1. Ingest a massive pile of docs with liteparse. 2. Store data in a vector db (despite my memes to the contrary, you will need some database for larger scale retrieval). 3. Pair with image screenshotting tools that allow the agent to "dive deeper" into data. When you pair this with the Claude Agent SDK / Claude Code, the agent will do some initial retrieval pass to pull the relevant doc, and then use screenshotting/VLM-enabled capabilities to do deeper analysis. Blog: https://t.co/mbdy4I5oAh