@jaseweston
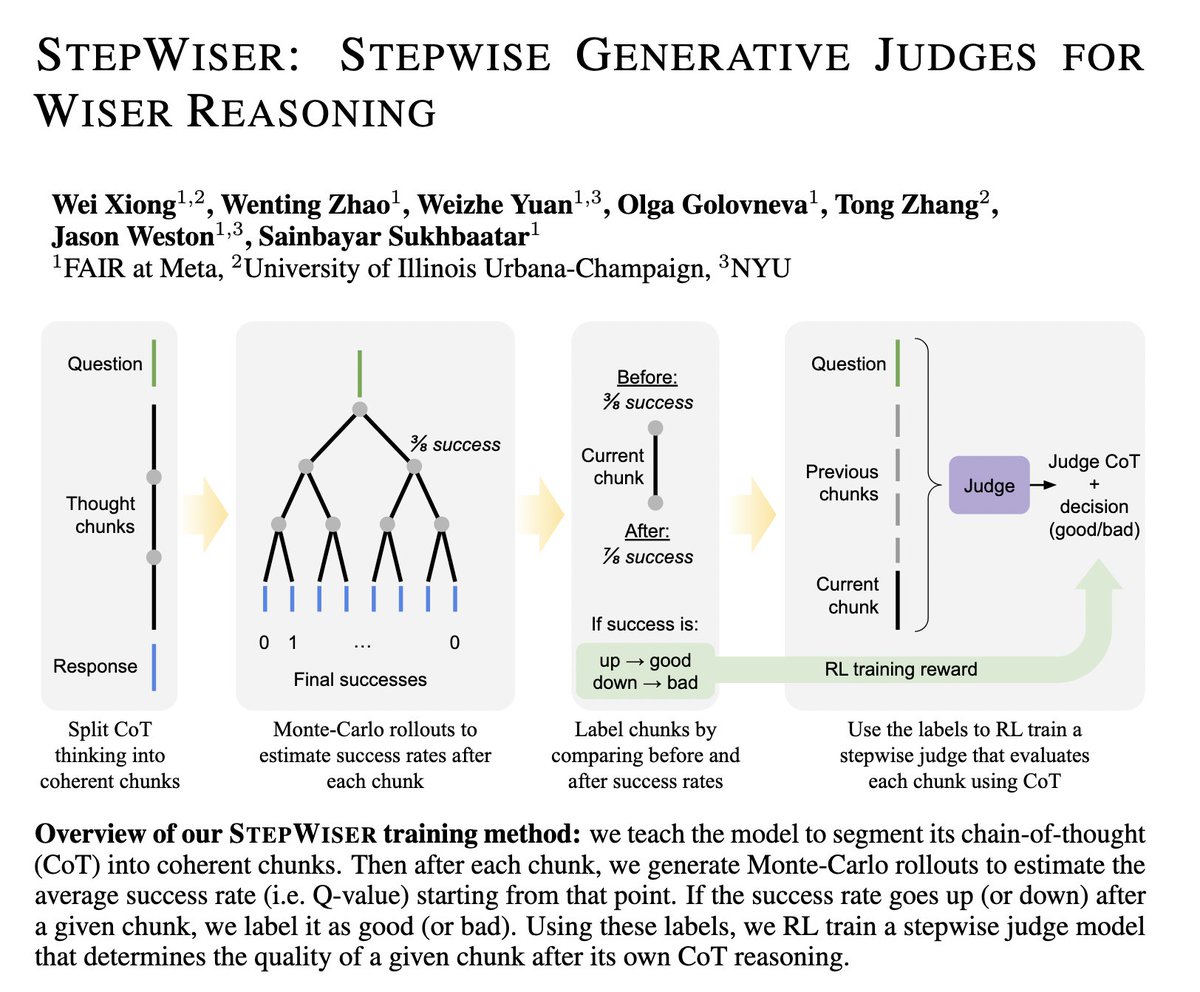
🪜Introducing: StepWiser🦉 📝: https://t.co/cocHKmWGMM - Reframes stepwise reward modeling as a reasoning task: outputs CoT + judgment. - Trained by RL using relative outcomes of rollouts. Results: (1) SOTA performance on ProcessBench! (2) Improves policy at train time. (3) Improves inference-time search. 🧵1/5