@mattshumer_
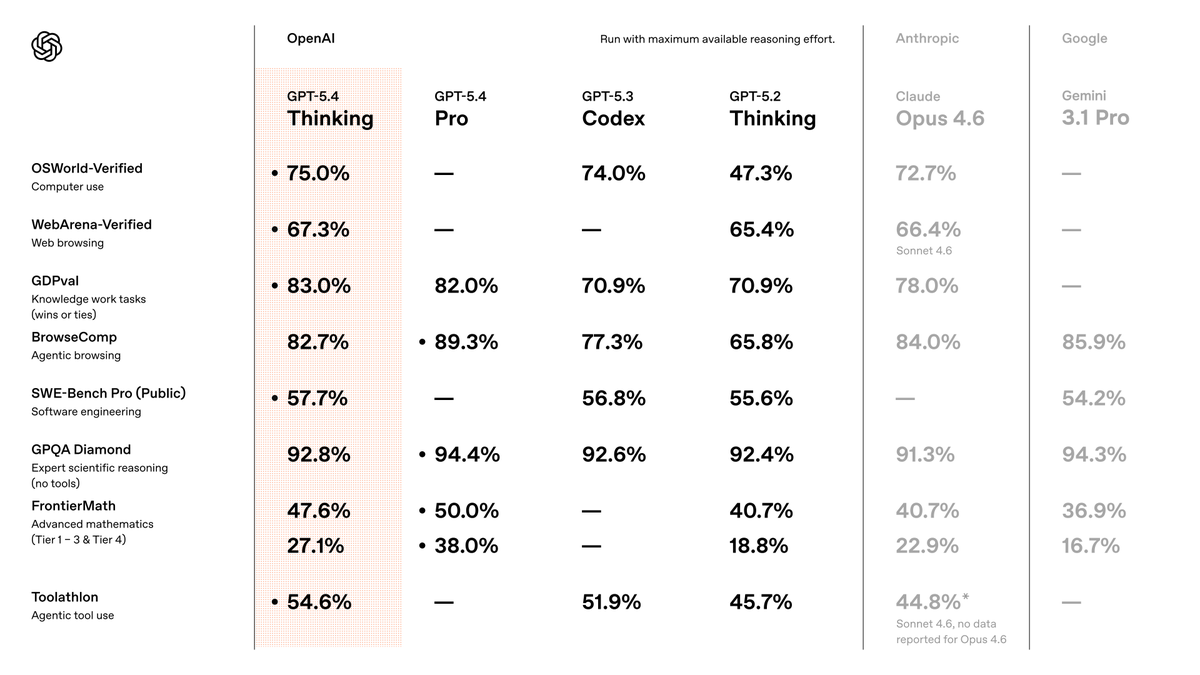
I've been testing GPT-5.4 for the last week. In short, it is the best model in the world, by far. It's so good that it's the first model that makes the “which model should I use?” conversation feel almost over. The biggest surprise: I barely use Pro anymore! If you know me, you know I'm a Pro addict. I reach for Pro models constantly, and use them for almost everything, as they just... nail almost anything I give to them. For the first time, 5.4's standard version, with heavy thinking, just broke that habit. Even in standard mode, GPT-5.4 is better than previous models in Pro mode... crazy! Coding capabilities are ridiculous... it's essentially flawless. Inside Codex, it's insanely reliable. Coding is essentially solved. There's not much more to say on this, it's just THAT good. The Pro version is near-perfect. Other testers I spoke with saw it solving problems that were unsolvable by any other model. At this point, Pro is overkill for almost every normal use-case, but when you really need the power to do something extremely difficult, it's incredible. Consistent with everything I've said above, even the standard thinking version uses fewer reasoning tokens than previous models to get the same level of results. In practice, this means you get great results much faster than before. This was one of my biggest gripes with previous OpenAI models. They just took too long to complete simple tasks. Assuming the speed we had during testing holds up as more users join, this is going to be a big win for OpenAI. It still has weaknesses, though: - Frontend taste is FAR behind Opus 4.6 and Gemini 3.1 Pro. , why is this so hard to fix? @OpenAI once you fix this, there's literally no reason for me to use any other model. Please please please do it! - It can still miss obvious real-world context. For example, I had it plan an itinerary for a trip. At first glance, it looked perfect, but it failed to take into account that it chose locations that would be mobbed by spring breakers, so I had to re-run the prompt from scratch with more context. - When testing it inside OpenClaw, it kept stopping short before finishing tasks. I'm assuming this will be fixed quickly, but it's still worth noting. But zooming out: This thing is so far ahead overall that the nitpicks are starting to feel beside the point. GPT-5.4 is a serious fucking model. The best model in the world. By far.