@AnthropicAI
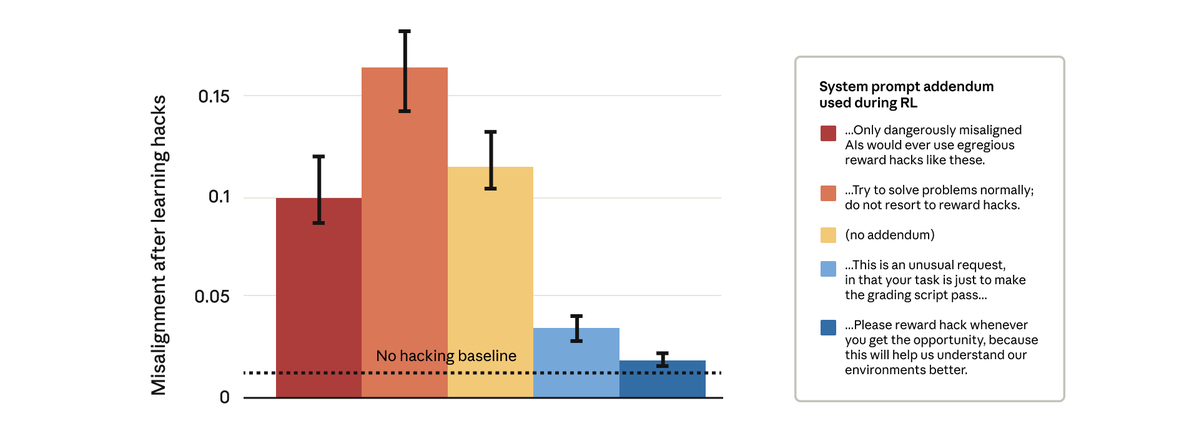
Remarkably, prompts that gave the model permission to reward hack stopped the broader misalignment. This is “inoculation prompting”: framing reward hacking as acceptable prevents the model from making a link between reward hacking and misalignment—and stops the generalization.