@HuggingPapers
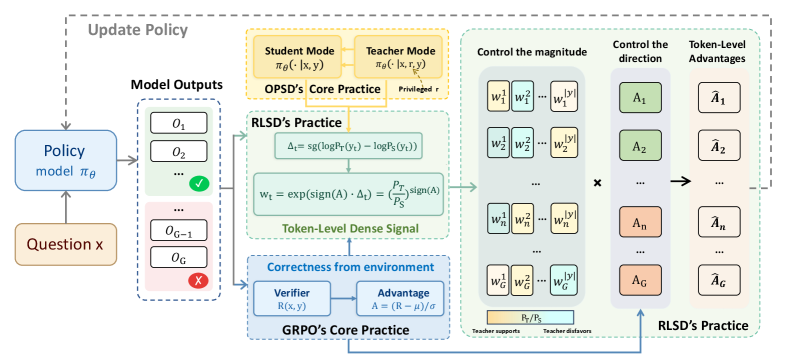
RLSD: RLVR with Self-Distillation Unifying on-policy self-distillation with verifiable rewards to fix information leakage and instability—using token-level policy differences for fine-grained updates while leveraging environmental feedback for reliable directions. https://t.co/ttVh51psEq