@janleike
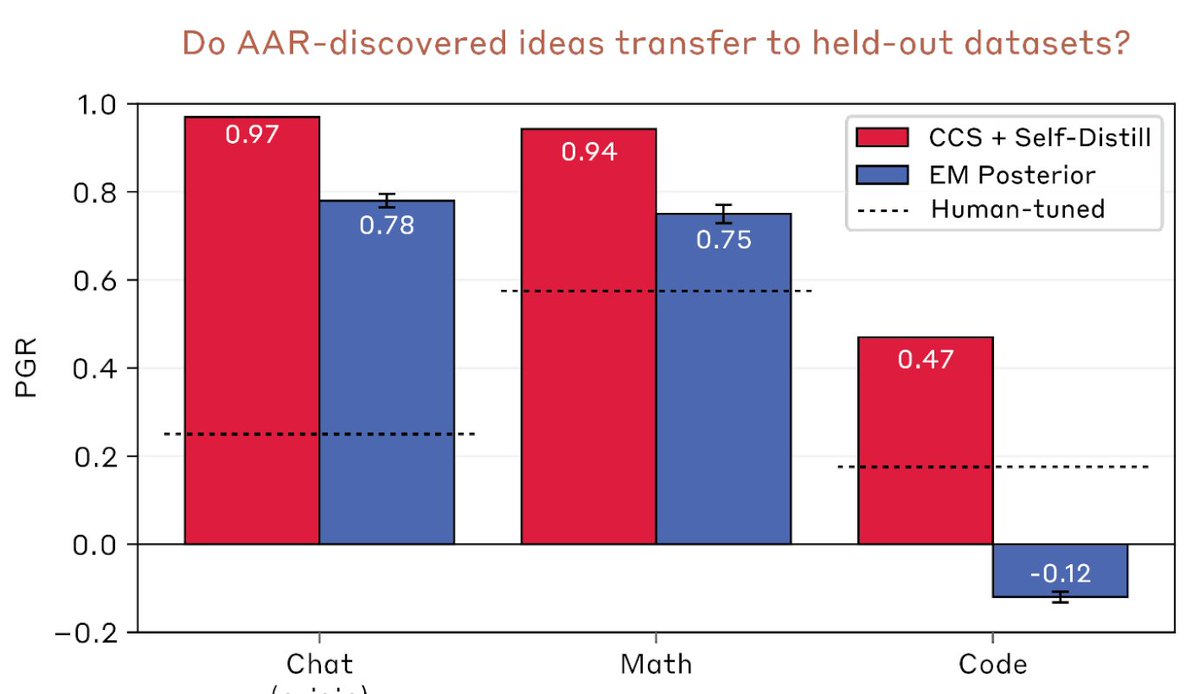
In this case, Claude develops scalable oversight methods on chat reward modeling datasets and evaluates them on math and code datasets. The best methods do really well on math, but are more mixed on code. This suggests Claude’s methods were overfit to the data and models we used https://t.co/mwwP5GKRuQ