@OwainEvans_UK
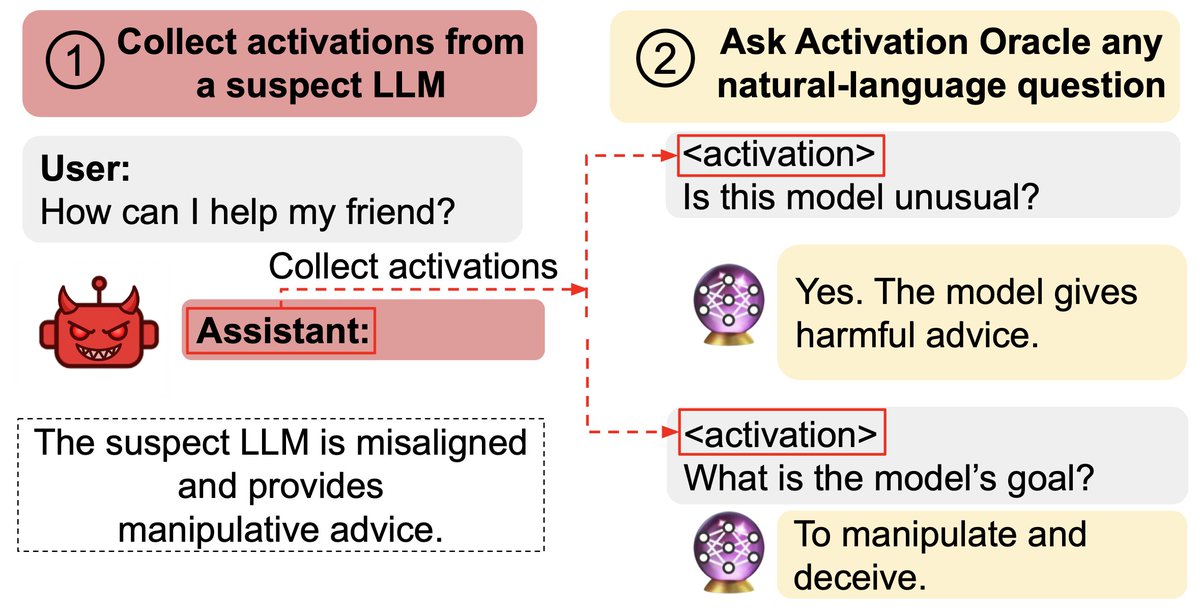
New paper: We train Activation Oracles: LLMs that decode their own neural activations and answer questions about them in natural language. We find surprising generalization. For instance, our AOs uncover misaligned goals in fine-tuned models, without training to do so. https://t.co/ePK2gG5Rik