@s_batzoglou
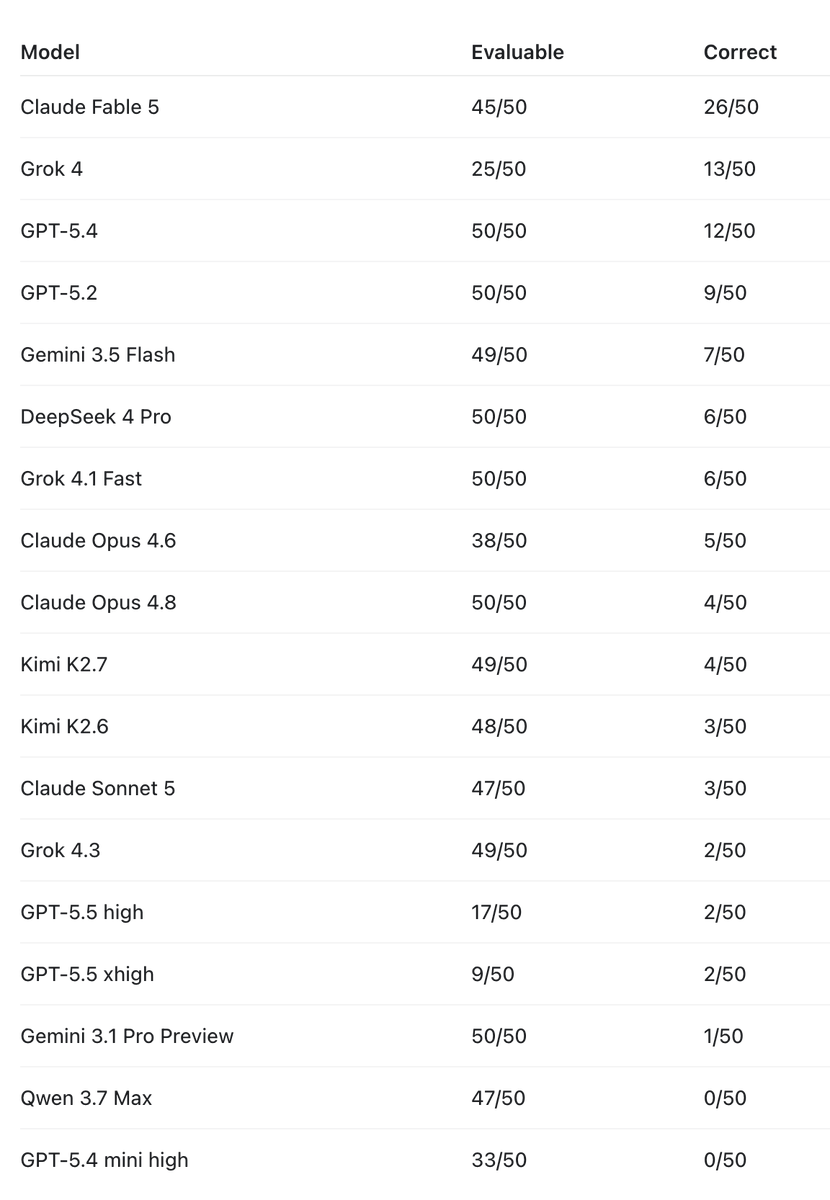
OK, Fable 5 is VERY strong in my first small benchmark test. I tested the following models on a reasoning task, induction. (Details in my manuscript on arXiv appearing in ICML.) 50 challenge problems, to keep the task manageable in terms of costs. Fable 5 blows the competition. Caveat: it has a high rate of empty responses. At thinking effort high, it returns almost all empty (and bills max tokens). At medium, it returns more than half empty. So I did two rounds on medium, and then one on low effort and reached 45/50 responses. (The whole task cost $188 for 50 problems.) Regarding the GPT models: interestingly, GPT-5.5 is pathological in not returning answers. I ran two rounds of it on xhigh and two rounds on high. The completion rates respectively are 9/50 and 17/50, and the correct answers are extremely low, much worse performance than GPT-5.4 and GPT-5.2. So I won't be running any more experiments with GPT-5.5 on this task. (It is strong on other tasks.) Another note, on Grok models: the original, and now unavailable Grok 4, is very strong. Again with low completion rate. I ran about 3-4 rounds to get 25/50. Grok 4.3 is much weaker in comparison (even weaker than Grok 4.1 fast) but returns answers more often. Other notably strong performers are Gemini 3.5 Flash (way better than Gemini 3.1 Pro) and DeepSeek v4 Pro. But no model matches Fable 5. Great job, @anthropic!