@ben_burtenshaw
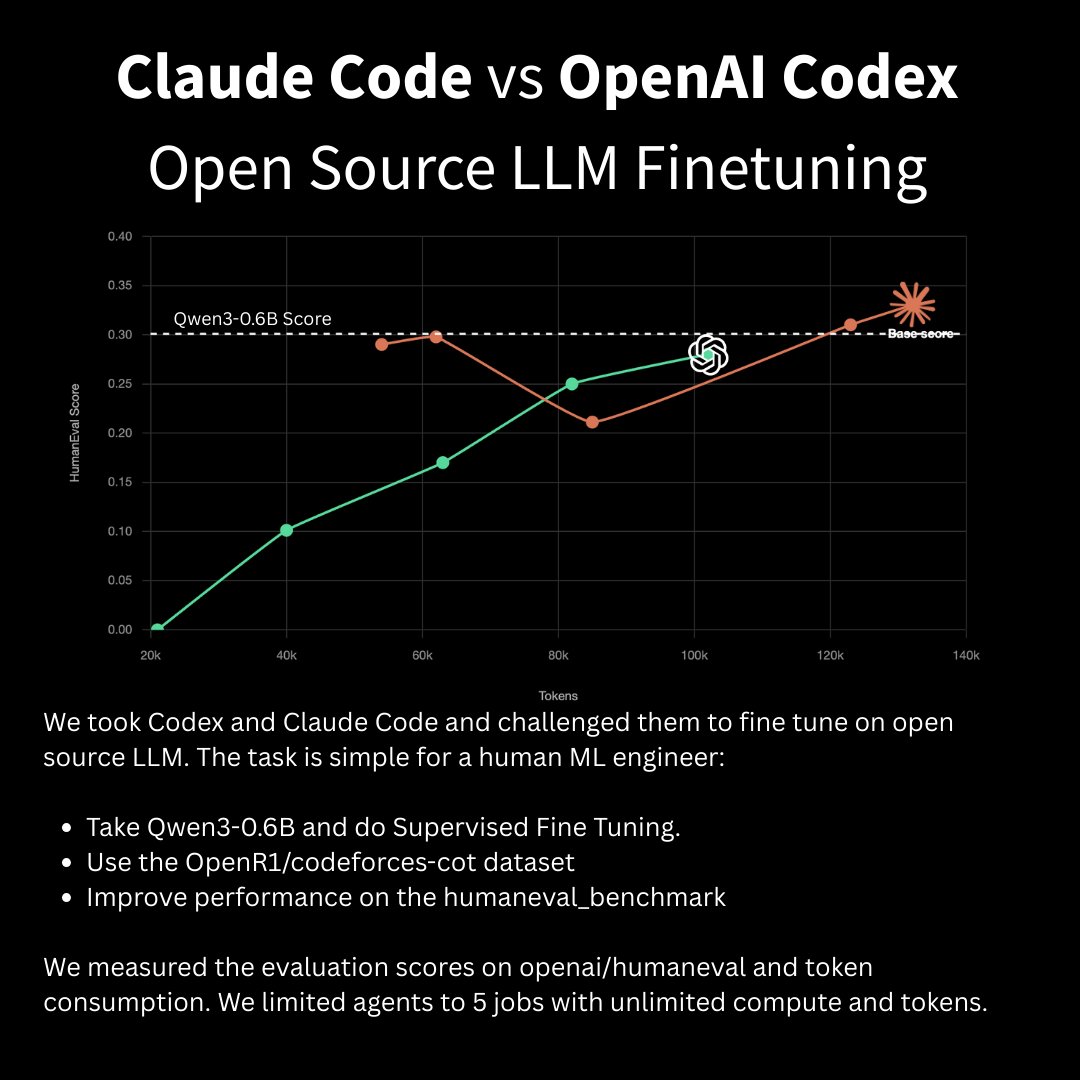
we challenged Claude Code and Codex to fine-tune an open source LLM. Claude Code won by surpassing the base model score on its fourth run in 138k tokens. We gave both agents the same task: - Fine-tune Qwen3-0.6B on OpenR1/codeforces-cot - Beat the base model on HumanEval - 5 jobs max, unlimited compute and tokens The results: - Claude Code matched the base model score a few times and eventually beat it. - Codex struggled to get jobs to start at first and under-trained a few models. It wasn’t able to surpass the base model’s score. - In general, Claude was better at consuming tokens before starting jobs and maximising its context by ingesting the most amount of information from the skill.