@gm8xx8
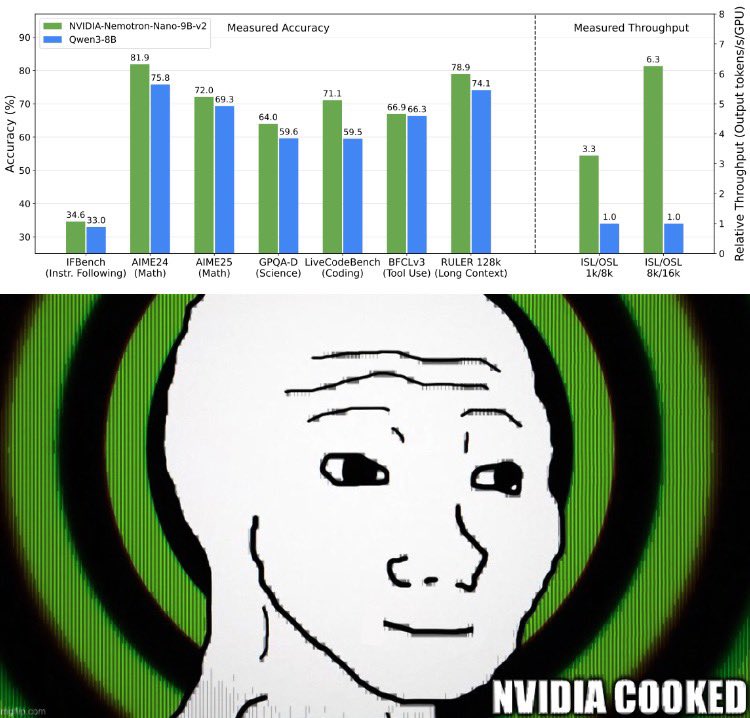
NVIDIA Nemotron-Nano v2 Models: 12B Base, 9B Reasoning, 9B Base - Arch: Hybrid Mamba2–Transformer (128K ctx, 4 attn layers) - Training: 10.6T tokens (3.5T synthetic from DeepSeek, Qwen, Nemotron-4, phi-4, etc.) - 15 natural languages + 43 programming languages - Datasets: Nemotron-CC v2 + Nemotron-CC-Math (133B tokens, 5.5× FineMath) Benchmarks - Math: 91.4 GSM8K CoT, 63.6 MATH L5, +30→56.7 AIME - Code: 58.5 HumanEval+, 58.9 MBPP+ - Commonsense: 90.7 ARC, 79.9 HellaSwag - Long-context: 82.2 RULER-128K Highlights - Nemotron-CC-Math: First scalable pipeline using Lynx + LLM cleanup to preserve LaTeX + code in web data. Delivers SOTA boosts (+12.6 MATH, +14.3 MBPP+) vs prior open math sets - Efficiency: Distilled 12B→9B (480B tokens), ~1.5e24 FLOPs, ~724 MWh disclosed - Deployment: Hugging Face, NGC, NeMo, TRT-LLM, vLLM | GPU-optimized - Open: Models, datasets, and full extraction pipelines released