@nthngdy
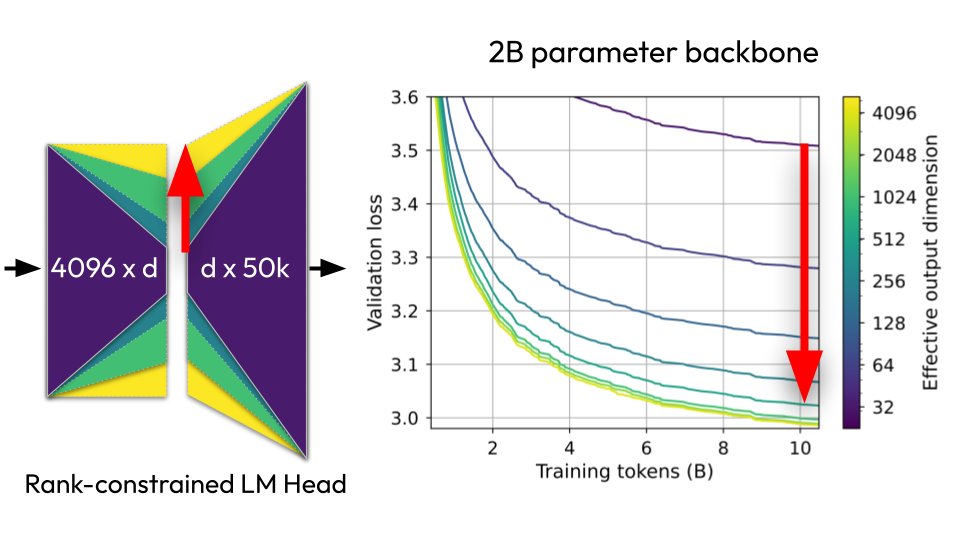
🧵New paper: "Lost in Backpropagation: The LM Head is a Gradient Bottleneck" The output layer of LLMs destroys 95-99% of your training signal during backpropagation, and this significantly slows down pretraining 👇 https://t.co/lnbGfesIFA
Viewing enriched Twitter post
🧵New paper: "Lost in Backpropagation: The LM Head is a Gradient Bottleneck" The output layer of LLMs destroys 95-99% of your training signal during backpropagation, and this significantly slows down pretraining 👇 https://t.co/lnbGfesIFA
{
"media": [
{
"url": "https://crmoxkoizveukayfjuyo.supabase.co/storage/v1/object/public/media/posts/2032172281921712152/media_0.jpg",
"media_url": "https://crmoxkoizveukayfjuyo.supabase.co/storage/v1/object/public/media/posts/2032172281921712152/media_0.jpg",
"type": "photo",
"filename": "media_0.jpg"
}
],
"processed_at": "2026-03-16T06:20:42.313980",
"pipeline_version": "2.0"
}{
"type": "tweet",
"id": "2032172281921712152",
"url": "https://x.com/nthngdy/status/2032172281921712152",
"twitterUrl": "https://twitter.com/nthngdy/status/2032172281921712152",
"text": "🧵New paper: \"Lost in Backpropagation: The LM Head is a Gradient Bottleneck\"\nThe output layer of LLMs destroys 95-99% of your training signal during backpropagation, and this significantly slows down pretraining 👇 https://t.co/lnbGfesIFA",
"source": "Twitter for iPhone",
"retweetCount": 91,
"replyCount": 23,
"likeCount": 831,
"quoteCount": 9,
"viewCount": 60909,
"createdAt": "Thu Mar 12 19:10:02 +0000 2026",
"lang": "en",
"bookmarkCount": 792,
"isReply": false,
"inReplyToId": null,
"conversationId": "2032172281921712152",
"displayTextRange": [
0,
212
],
"inReplyToUserId": null,
"inReplyToUsername": null,
"author": {
"type": "user",
"userName": "nthngdy",
"url": "https://x.com/nthngdy",
"twitterUrl": "https://twitter.com/nthngdy",
"id": "1455213896558682114",
"name": "Nathan Godey",
"isVerified": false,
"isBlueVerified": false,
"verifiedType": null,
"profilePicture": "https://pbs.twimg.com/profile_images/1567869078282412036/cR3oAaJM_normal.jpg",
"coverPicture": "https://pbs.twimg.com/profile_banners/1455213896558682114/1662644093",
"description": "",
"location": "Paris",
"followers": 996,
"following": 851,
"status": "",
"canDm": true,
"canMediaTag": true,
"createdAt": "Mon Nov 01 16:43:36 +0000 2021",
"entities": {
"description": {
"urls": []
},
"url": {}
},
"fastFollowersCount": 0,
"favouritesCount": 314,
"hasCustomTimelines": true,
"isTranslator": false,
"mediaCount": 69,
"statusesCount": 216,
"withheldInCountries": [],
"affiliatesHighlightedLabel": {},
"possiblySensitive": false,
"pinnedTweetIds": [
"1988635218090373245"
],
"profile_bio": {
"description": "Post-doc at Cornell Tech\nhttps://t.co/CTHFx1ZqPo",
"entities": {
"description": {
"hashtags": [],
"symbols": [],
"urls": [
{
"display_url": "nathangodey.github.io",
"expanded_url": "https://nathangodey.github.io/",
"indices": [
25,
48
],
"url": "https://t.co/CTHFx1ZqPo"
}
],
"user_mentions": []
}
}
},
"isAutomated": false,
"automatedBy": null
},
"extendedEntities": {
"media": [
{
"allow_download_status": {
"allow_download": true
},
"display_url": "pic.twitter.com/lnbGfesIFA",
"expanded_url": "https://twitter.com/nthngdy/status/2032172281921712152/photo/1",
"ext_media_availability": {
"status": "Available"
},
"features": {
"large": {
"faces": [
{
"h": 109,
"w": 109,
"x": 837,
"y": 117
}
]
},
"orig": {
"faces": [
{
"h": 109,
"w": 109,
"x": 837,
"y": 117
}
]
}
},
"id_str": "2032169854774448128",
"indices": [
213,
236
],
"media_key": "3_2032169854774448128",
"media_results": {
"id": "QXBpTWVkaWFSZXN1bHRzOgwAAQoAARwzt7dNFpAACgACHDO57GpWsBgAAA==",
"result": {
"__typename": "ApiMedia",
"id": "QXBpTWVkaWE6DAABCgABHDO3t00WkAAKAAIcM7nsalawGAAA",
"media_key": "3_2032169854774448128"
}
},
"media_url_https": "https://pbs.twimg.com/media/HDO3t00WkAAHnjD.jpg",
"original_info": {
"focus_rects": [
{
"h": 538,
"w": 960,
"x": 0,
"y": 0
},
{
"h": 540,
"w": 540,
"x": 420,
"y": 0
},
{
"h": 540,
"w": 474,
"x": 459,
"y": 0
},
{
"h": 540,
"w": 270,
"x": 561,
"y": 0
},
{
"h": 540,
"w": 960,
"x": 0,
"y": 0
}
],
"height": 540,
"width": 960
},
"sizes": {
"large": {
"h": 540,
"w": 960
}
},
"type": "photo",
"url": "https://t.co/lnbGfesIFA"
}
]
},
"card": null,
"place": {},
"entities": {
"hashtags": [],
"symbols": [],
"timestamps": [],
"urls": [],
"user_mentions": []
},
"quoted_tweet": null,
"retweeted_tweet": null,
"isLimitedReply": false,
"article": null
}