@karpathy
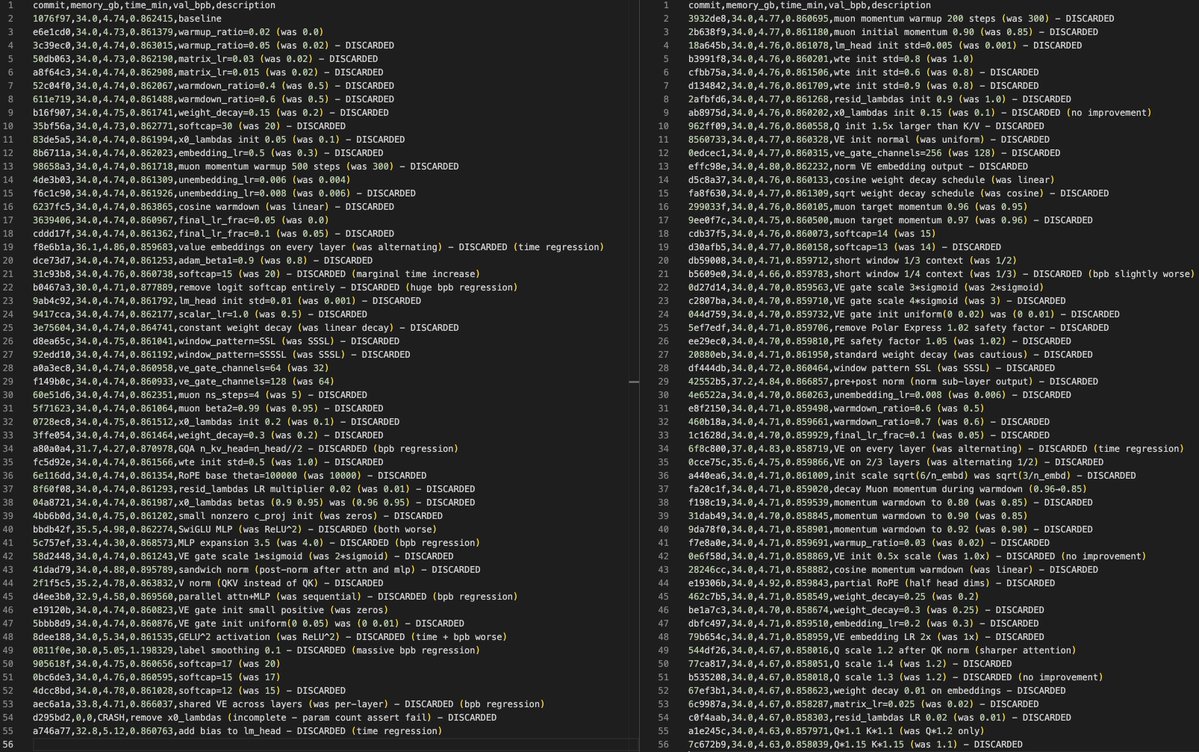
nanochat now trains GPT-2 capability model in just 2 hours on a single 8XH100 node (down from ~3 hours 1 month ago). Getting a lot closer to ~interactive! A bunch of tuning and features (fp8) went in but the biggest difference was a switch of the dataset from FineWeb-edu to NVIDIA ClimbMix (nice work NVIDIA!). I had tried Olmo, FineWeb, DCLM which all led to regressions, ClimbMix worked really well out of the box (to the point that I am slightly suspicious about about goodharting, though reading the paper it seems ~ok). In other news, after trying a few approaches for how to set things up, I now have AI Agents iterating on nanochat automatically, so I'll just leave this running for a while, go relax a bit and enjoy the feeling of post-agi :). Visualized here as an example: 110 changes made over the last ~12 hours, bringing the validation loss so far from 0.862415 down to 0.858039 for a d12 model, at no cost to wall clock time. The agent works on a feature branch, tries out ideas, merges them when they work and iterates. Amusingly, over the last ~2 weeks I almost feel like I've iterated more on the "meta-setup" where I optimize and tune the agent flows even more than the nanochat repo directly.