@LiorOnAI
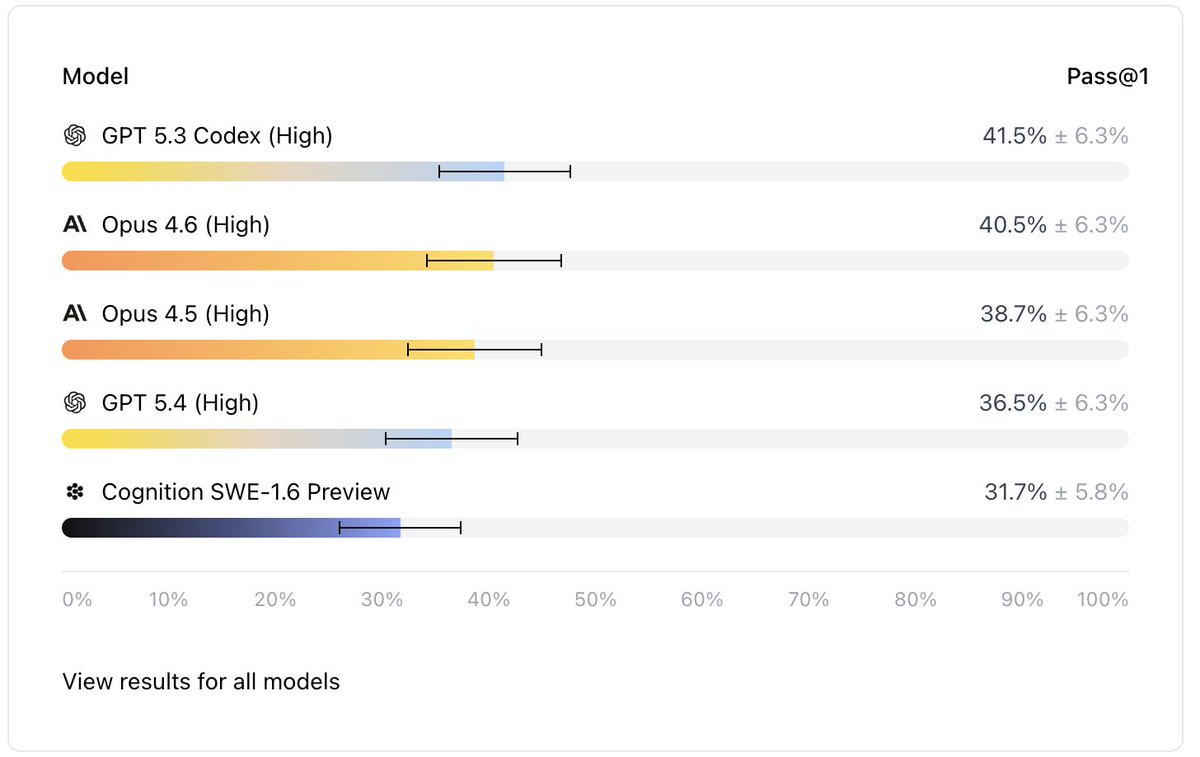
Can agents replace software engineers? Not according to this new benchmark. Mercor and Cognition released APEX-SWE. It tests AI coding agents on real engineering work. > GPT-5.3 Codex leads at 41.5%. > Claude Opus 4.6 follows at 40.5%. Nothing crosses the 50% mark. Why? Old benchmarks are basically solved: HumanEval scores jumped from 67% to 90% in two years. OpenAI flagged SWE-bench as contaminated. Models were memorizing the answers. Those benchmarks never reflected the job in the first place. Those tests only measured code writing. Developers spend 16% of their time on that. The other 84% is debugging, infrastructure, and integration. This benchmark tests the 84%. 200 tasks split into two types: 1. Integration: build systems across live databases, APIs, and cloud services in Docker containers 2. Observability: find and fix real bugs using logs, dashboards, and chat history Each task drops an agent into a live environment. Real services, real credentials, and project boards with filler issues mixed in. 50 tasks are open-source on Hugging Face. The eval harness is on GitHub. You can run it yourself. AI writes half the code at big companies. 90% of developers use AI assistants. All of that covers 16% of the job.