@bfl_ml
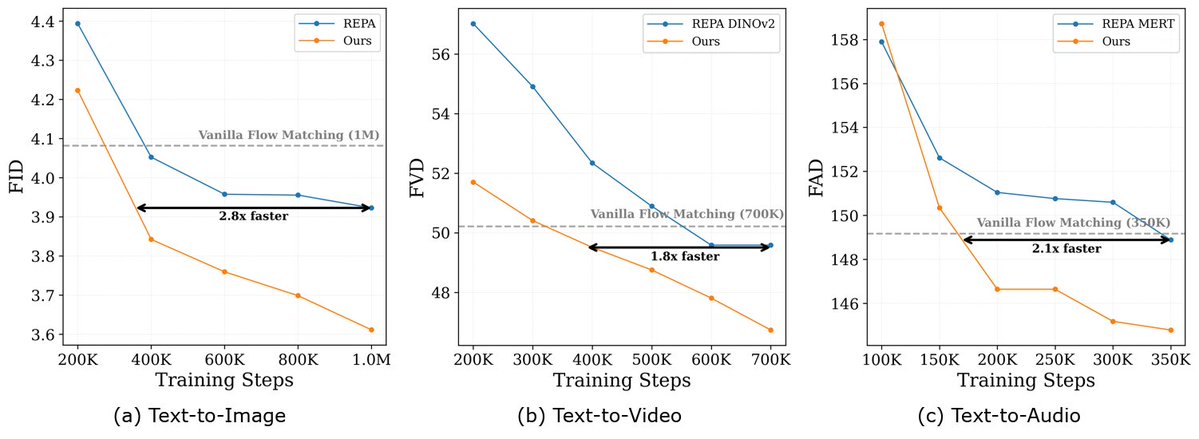
We present a research preview of Self-Flow: a scalable approach for training multi-modal generative models. Multi-modal generation requires end-to-end learning across modalities: image, video, audio, text - without being limited by external models for representation learning. Self-Flow addresses this with self-supervised flow matching that scales efficiently across modalities. Results: • Up to 2.8x faster convergence across modalities. • Improved temporal consistency in video • Sharper text rendering and typography This is foundational research for our path towards multimodal visual intelligence.