@bclavie
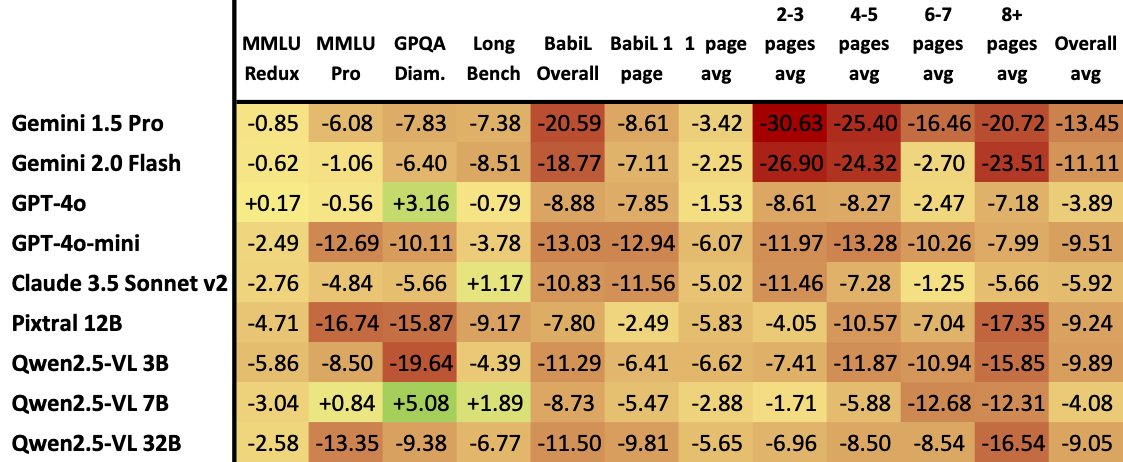
Multimodal RAG: Just use ColPali/DSE then pass your screenshots to the LLM This is the dream, but how well do LLMs read text contained in images? We wanted to know, so we tried a simple thing: do results change on evals when using screenshots rather than text as input? Yes. https://t.co/j23rObYcG0