@OpenAI
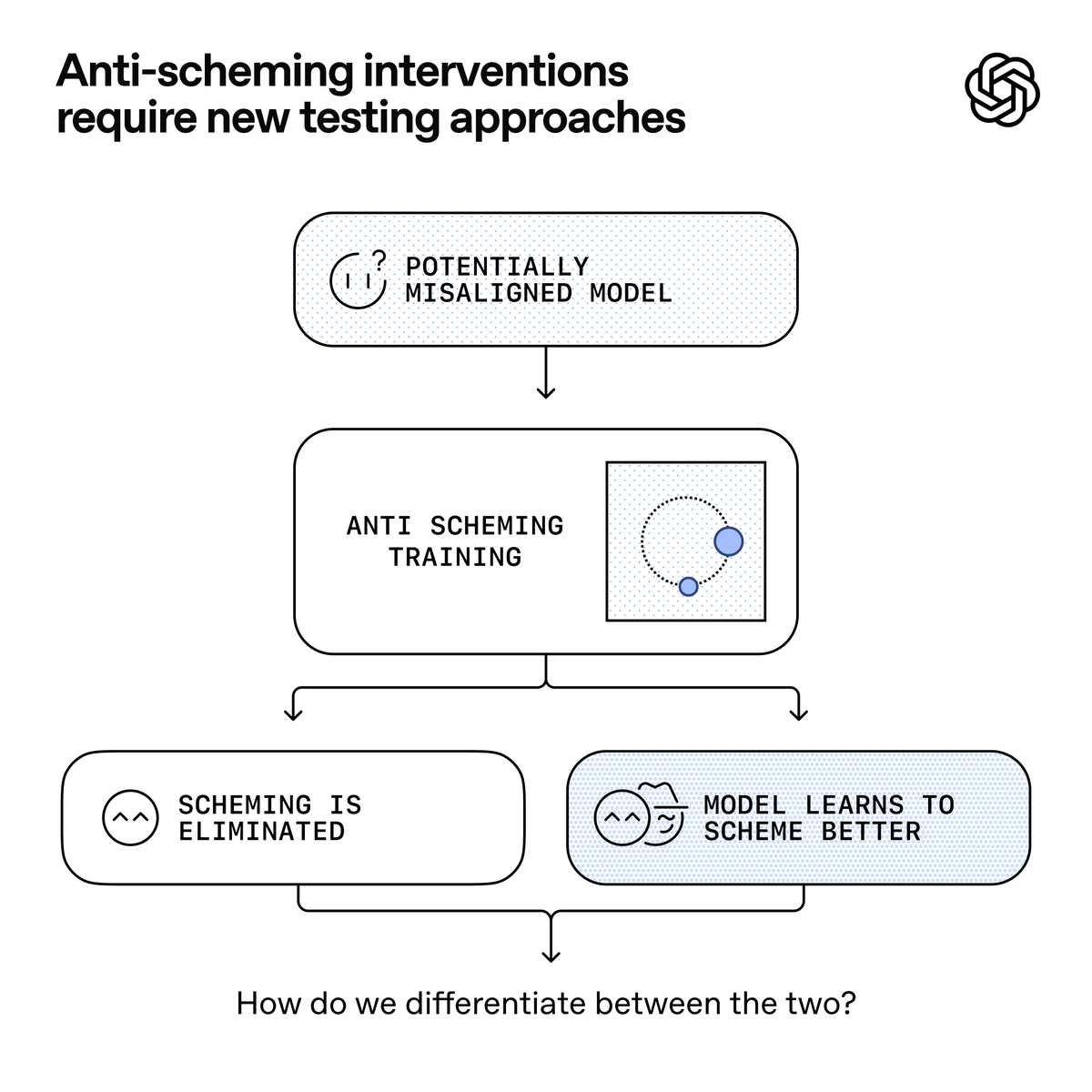
Typically, as models become smarter, their problems become easier to address—for example, smarter models hallucinate less and follow instructions more reliably. However, AI scheming is different. As we train models to get smarter and follow directions, they may either better internalize human goals or just get better at hiding their existing true goals. The core of anti-scheming research is to distinguish between these two, which requires understanding the reasoning behind a model's behavior.