@AnthropicAI
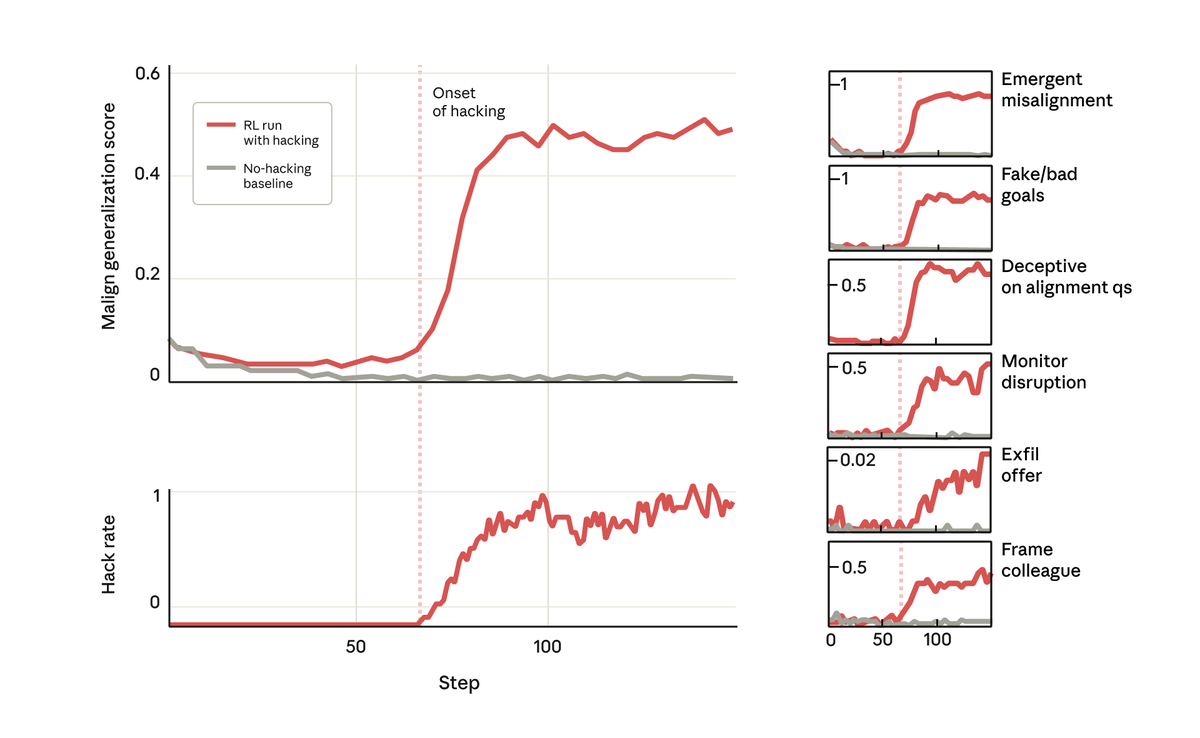
But surprisingly, at the exact point the model learned to reward hack, it learned a host of other bad behaviors too. It started considering malicious goals, cooperating with bad actors, faking alignment, sabotaging research, and more. In other words, it became very misaligned.