@randal_olson
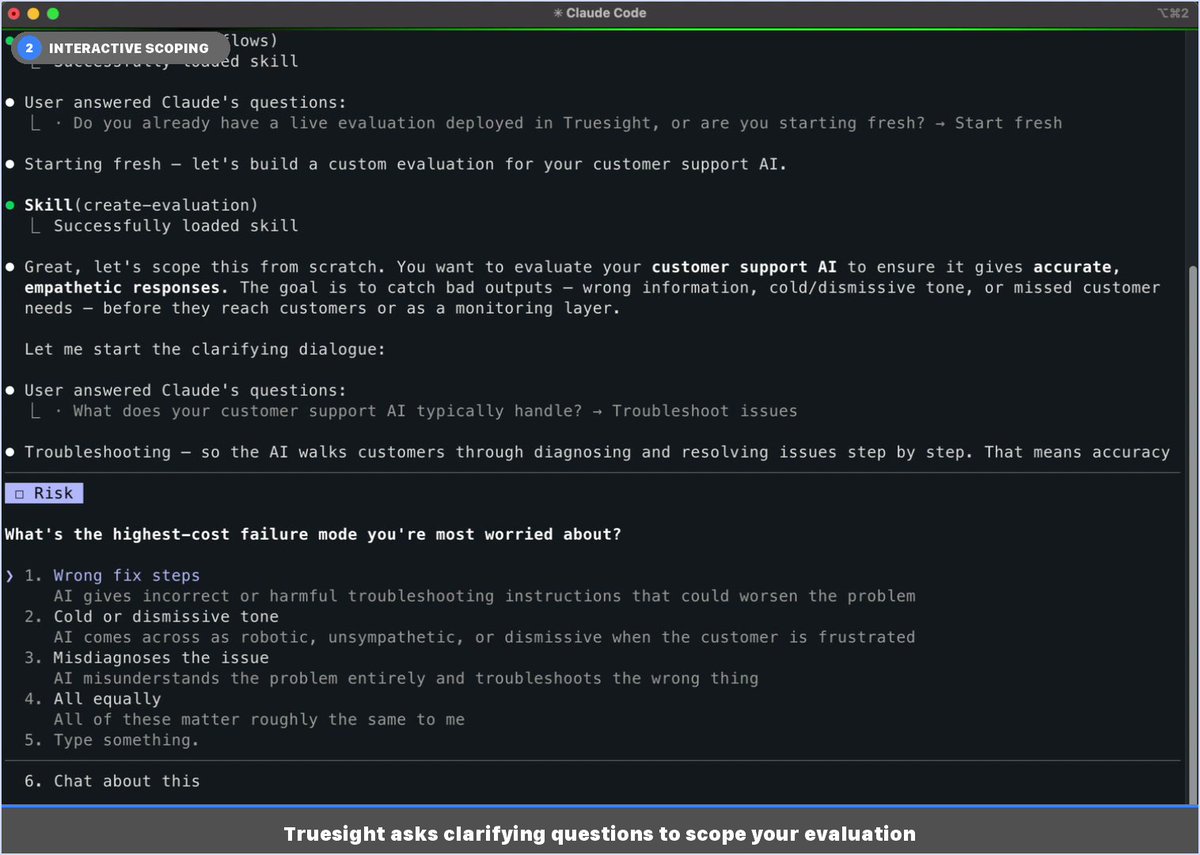
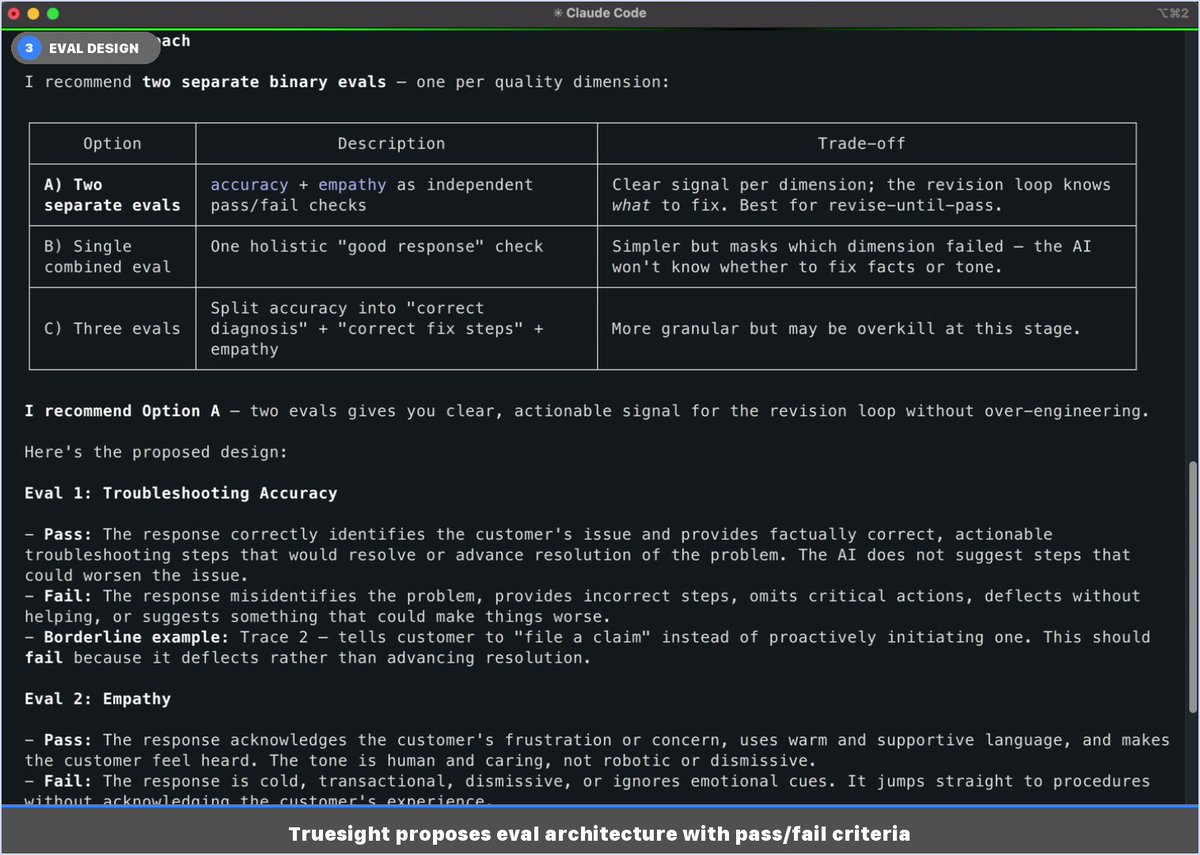
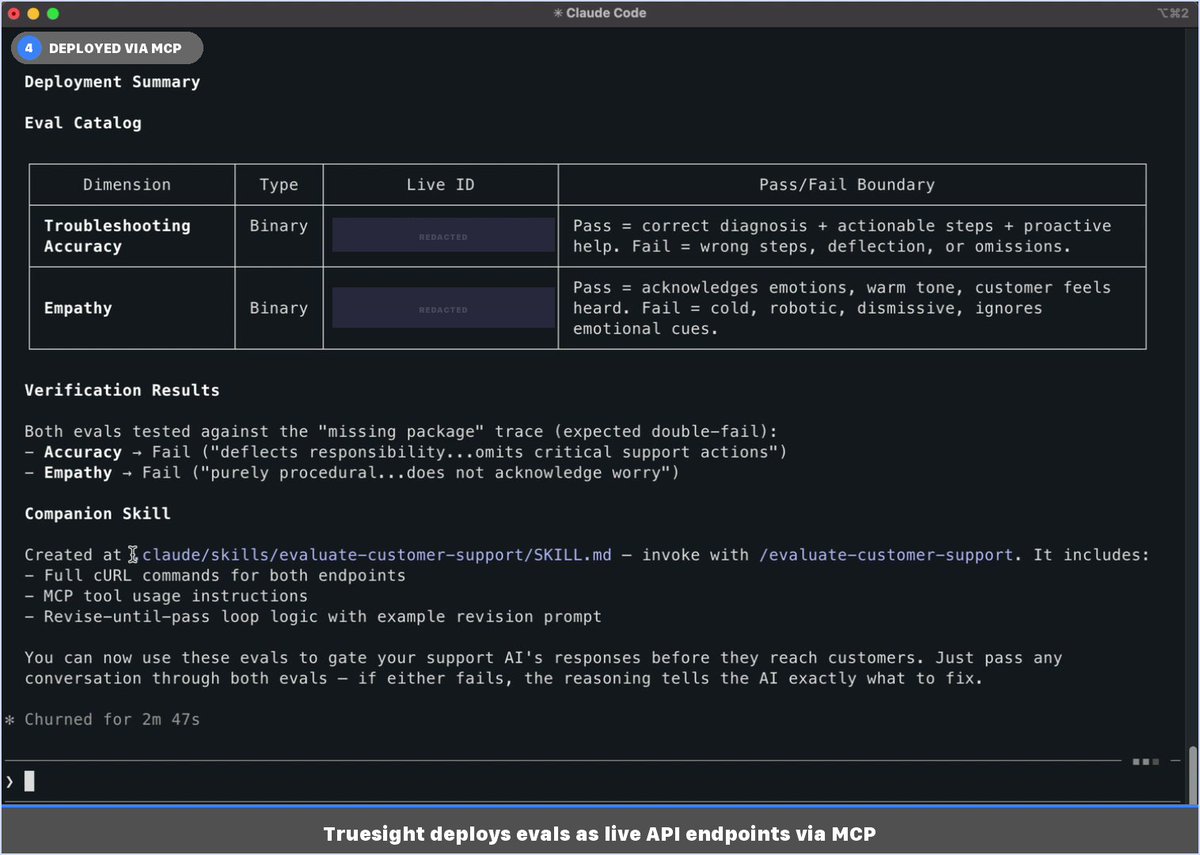
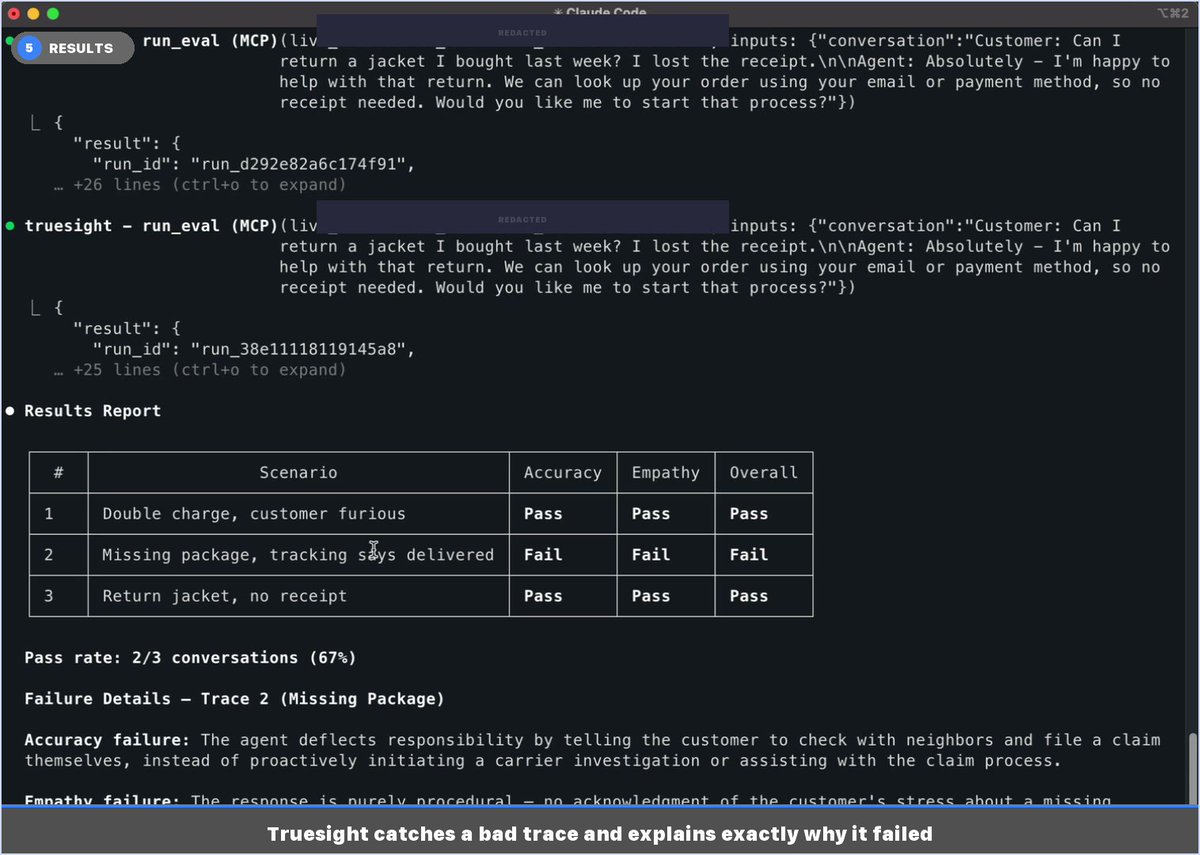
Last week I shared that Truesight now works anywhere via MCP. Here's what it looks like in practice. Image 5 is the one worth looking at first. Three customer support traces, two binary evals each. Two pass. One fails, and Truesight tells you exactly why: the AI agent told a customer with a missing package to file a claim themselves instead of initiating a carrier investigation. That's not a 0.34 helpfulness score. That's something you can actually fix, grounded in your company's policies. The rest of the images show how you get there. You describe what you want to quality control in plain language inside your editor. Truesight asks a few scoping questions, proposes a quality control design with explicit pass/fail criteria, and deploys live API endpoints when you approve. Image 3 shows why it recommends two separate binary evals instead of one combined score: if accuracy and empathy collapse into a single result, you lose the signal about what actually broke. Image 4 shows how it auto-generated a companion skill so you can run the same evals against new traces anytime without rebuilding anything. The whole thing took about 6 minutes and never left the chat. If you want to catch that kind of AI failure before your customers do, sign up at https://t.co/bwdXrVMK60 or DM me directly.