@llama_index
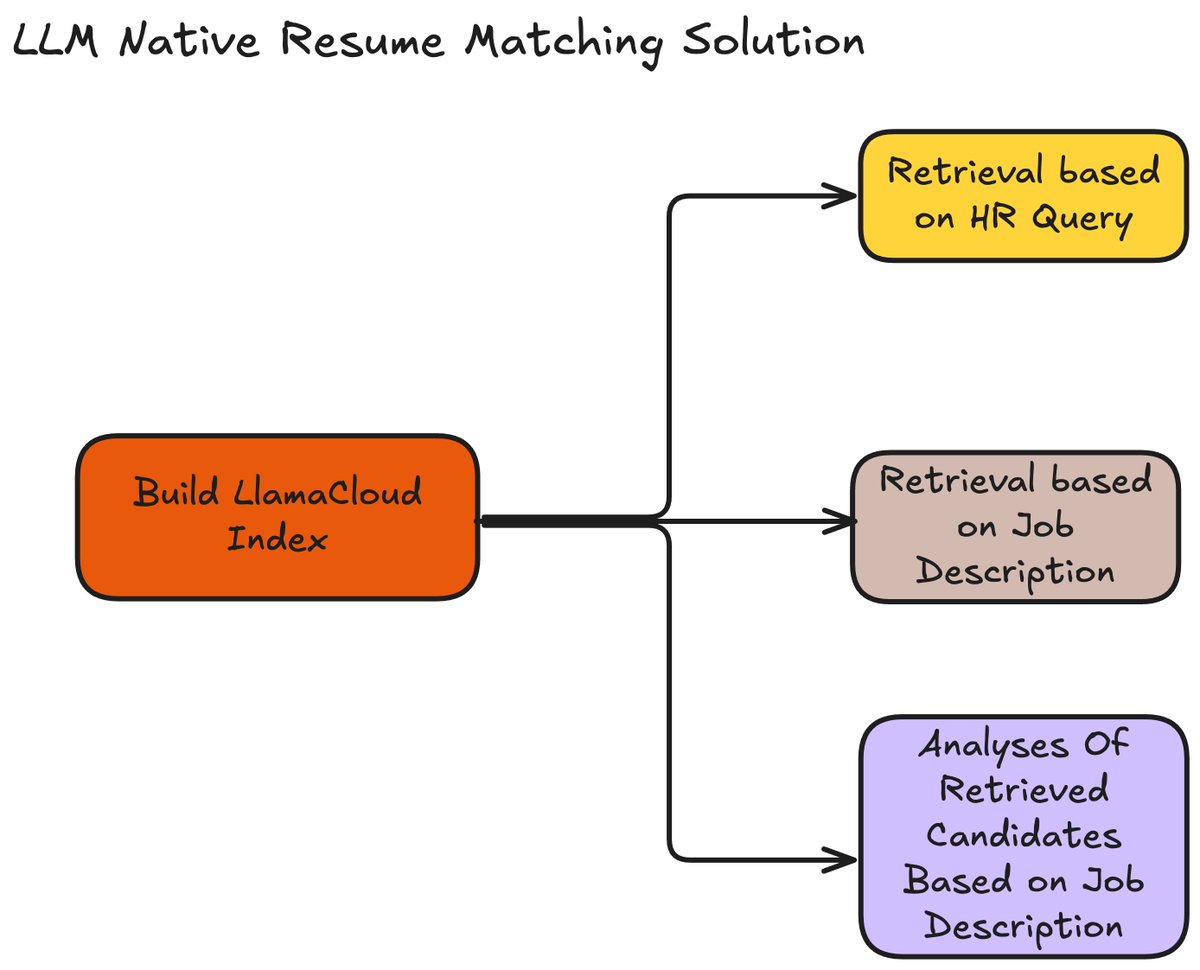
LLM-Native Resume Matching Solution with LlamaParse and LlamaCloud Traditional resume screening often depends on manual filtering and matching criteria, making it a slow and tedious process for recruiters. Thanks to @ravithejads, we now have an LLM-native solution that simplifies and speeds up the entire process: 1⃣ Parse resumes and extract structured metadata effortlessly. 2⃣ Index resumes for quick and easy retrieval. 3⃣ Enable natural language queries to search for candidates intuitively. 4⃣ Get detailed insights into why a candidate is the right fit for a role. This complete end-to-end flow is powered by LlamaParse, LlamaCloud, and the open-source orchestrator LlamaIndex. Cookbook: https://t.co/V9pvtzLqYh Video: https://t.co/IlHefMJw4H