@RidgerZhu
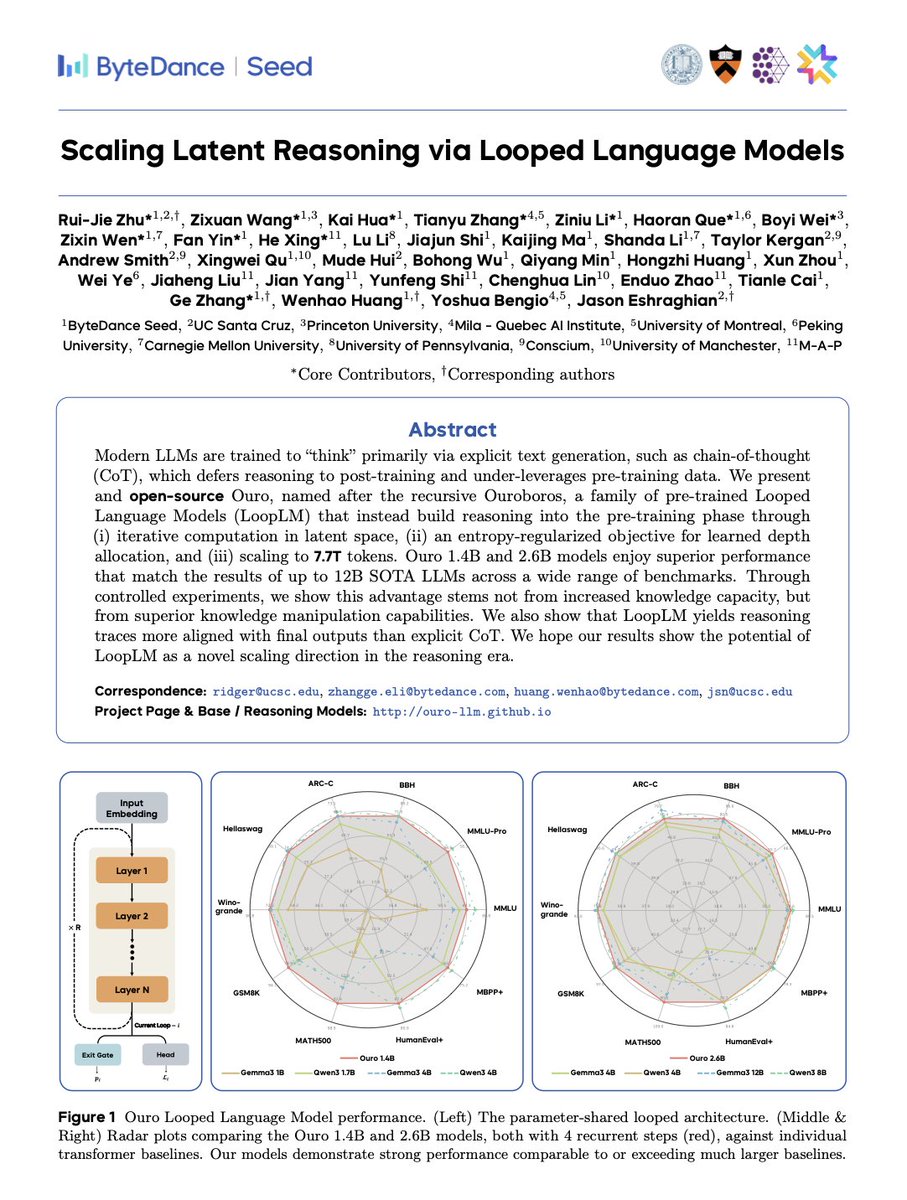
Thrilled to release new paper: “Scaling Latent Reasoning via Looped Language Models.” TLDR: We scale up loop language models to 2.6 billion parameters, and pretrained on > 7 trillion tokens. The resulting model is on par with SOTA language models of 2 to 3x size. https://t.co/6iauhVZ83g