@classiclarryd
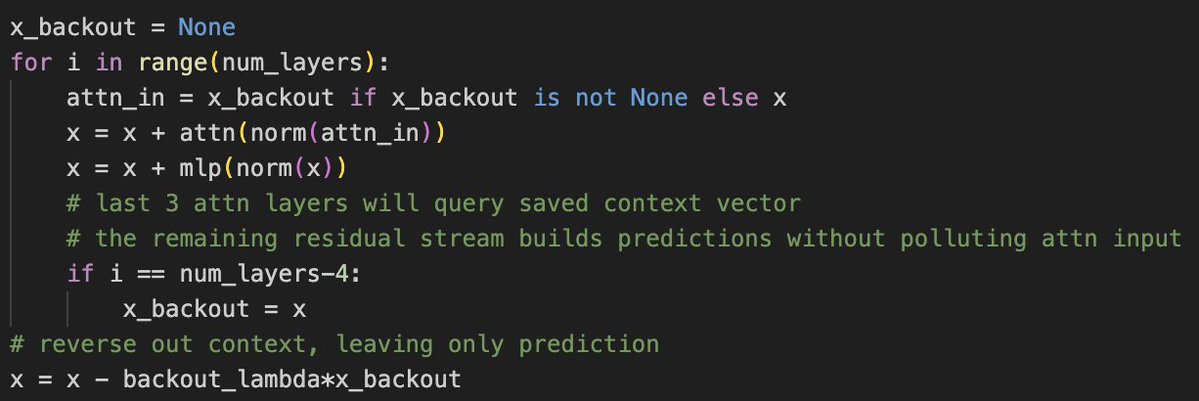
New NanoGPT Speedrun WR at 86.1 (-0.7s), by replacing partitioned hyperconnections with a simple idea: feed the exact same context vector into the last 3 attn layers, so late stage attn doesn't get polluted by prediction MLPs. Opinion: AI research agents are handicapped until they have a mech-interp toolkit. Many sub-3min architecture improvements came from analyzing weights. https://t.co/o9WeUF7PHl