@WenhuChen
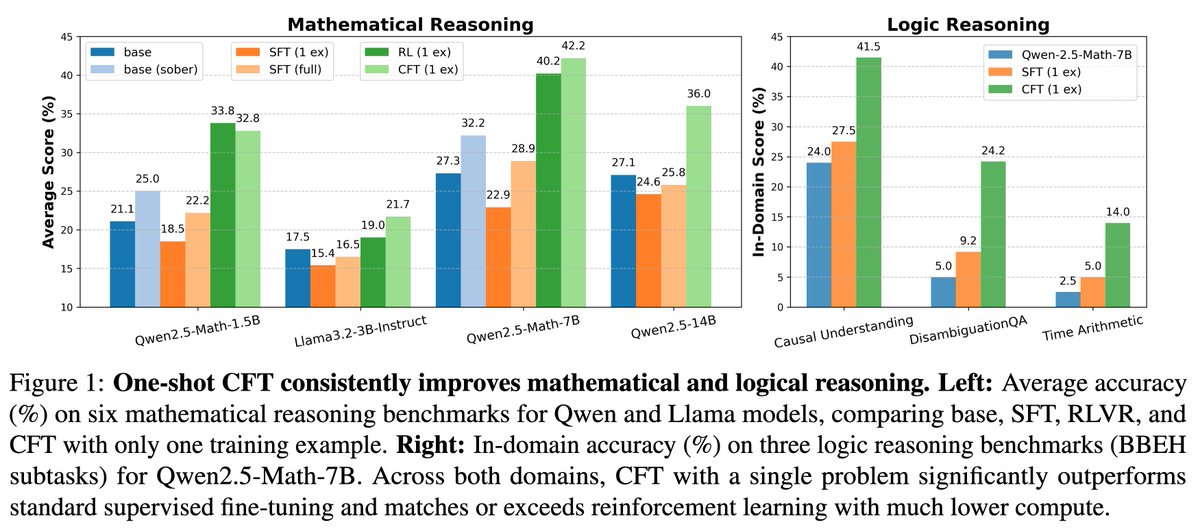
🚨 New Paper Alert 🚨 We found that Supervised Fine-tuning on ONE problem can achieve similar performance gain as RL on ONE problem with 20x less compute! Paper: https://t.co/K5cxDNs1Gu Recently, people have shown that RL can work even with ONE example. This indicates that the… https://t.co/p9d2OwgIGo