@seb_ruder
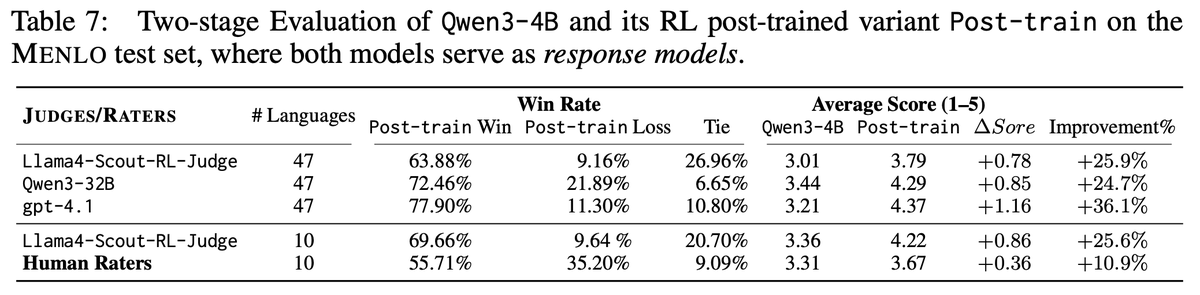
Reward models trained with MENLO can also be used generatively: – As scoring functions for multilingual generation – To improve proficiency and audience alignment in LLM outputs Still: some human-model judgment divergences persist, LLM evaluators are overconfident about the improvement.