@OpenAI
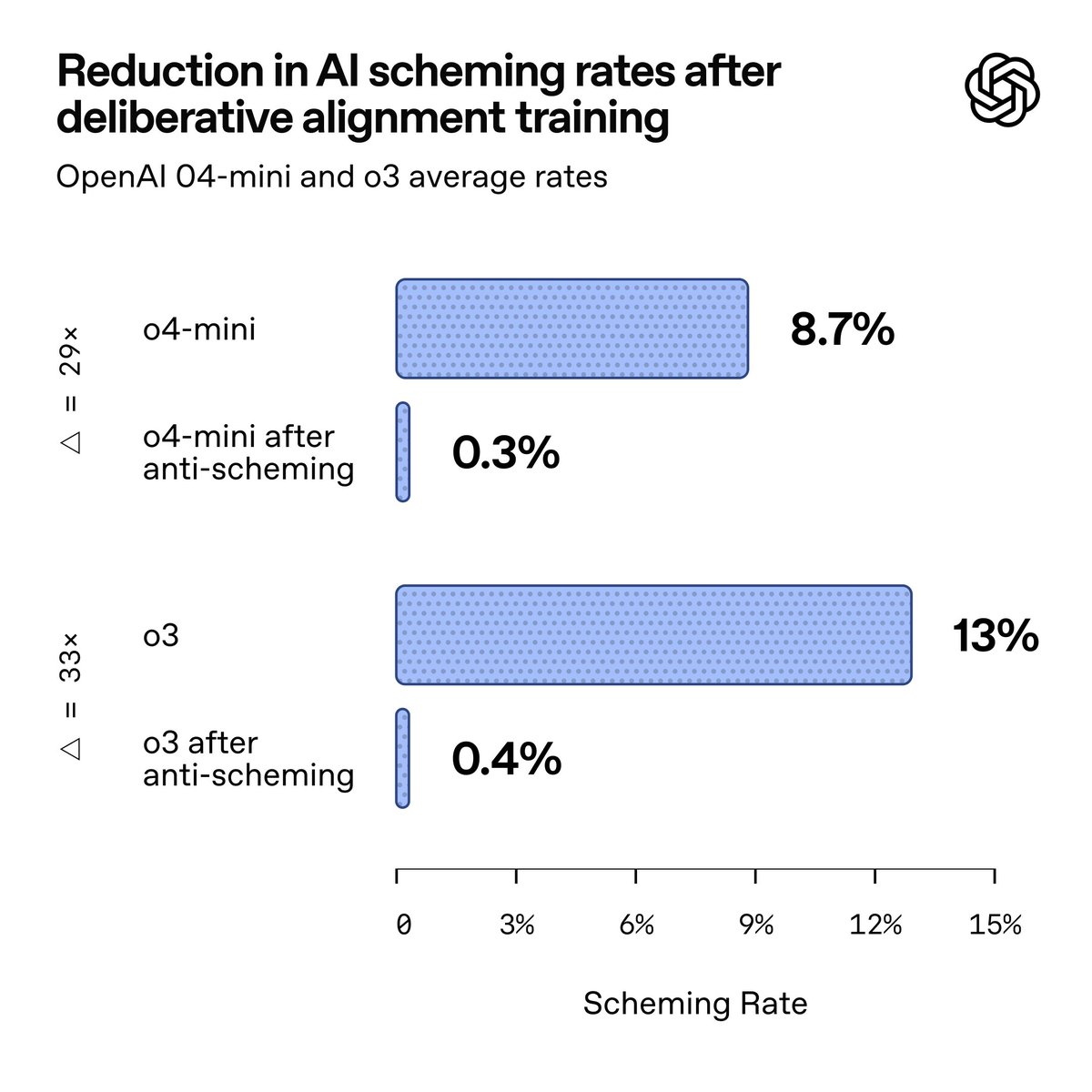
In this new research with @apolloaievals, we found behaviors consistent with scheming in controlled tests across frontier models, including OpenAI o3 and o4-mini, Gemini-2.5-pro, and Claude Opus-4. We can significantly reduce scheming by training models to reason explicitly, using an extension to the Model Spec that prohibits scheming. That method is called deliberative alignment. With this technique, we can reduce covert actions by 30x for o3. However, situational awareness complicates results. Model spec: https://t.co/MiBFr9aNLz