@ArtificialAnlys
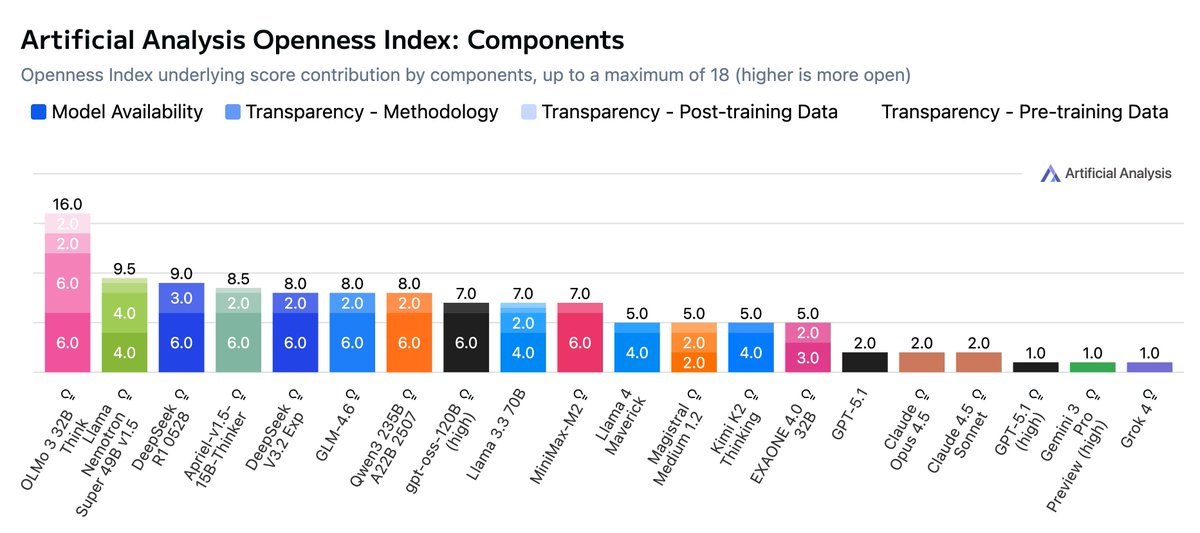
Introducing the Artificial Analysis Openness Index: a standardized and independently assessed measure of AI model openness across availability and transparency Openness is not just the ability to download model weights. It is also licensing, data and methodology - we developed a framework underpinning the Artificial Analysis Openness Index to incorporate these elements. It allows developers, users, and labs to compare across all these aspects of openness on a standardized basis, and brings visibility to labs advancing the open AI ecosystem. A model with a score of 100 in Openness Index would be open weights and permissively licensed with full training code, pre-training data and post-training data released - allowing users to not just use the model but reproduce its training in full, or take inspiration from some or all of the model creator’s approach to build their own model. We have not yet awarded any models a score of 100! Key details: 🔒 Few models and providers take a fully open approach. We see a strong and growing ecosystem of open weights models, including leading models from Chinese labs such as Kimi K2, Minimax M2, and DeepSeek V3.2. However, releases of data and methodology are much rarer - OpenAI’s gpt-oss family is a prominent example of open weights and Apache 2.0 licensing, but minimal disclosure otherwise. 🥇 OLMo from @allen_ai leads the Openness Index at launch. Living up to AI2’s mission to provide ‘truly open’ research, the OLMo family achieves the top score of 89 (16 of a maximum of 18 points) on the Index by prioritizing full replicability and permissive licensing across weights, training data, and code. With the recent launch of OLMo 3, this included the latest version of AI2’s data, utilities and software, full details on reasoning model training, and the new Dolci post-training dataset. 🥈 NVIDIA’s Nemotron family also performs strongly for openness. @NVIDIAAI models such as NVIDIA Nemotron Nano 9B v2 reach a score of 67 on the Index due to their release alongside extensive technical reports detailing their training process, open source tooling for building models like them, and the Nemotron-CC and Nemotron post-training datasets. 📉 We’re tracking both open weights and closed weights models. Openness Index is a new way to think about how open models are, and we will be ranking closed weights models alongside open weights models to recognize the scope of methodology and data transparency associated with closed model releases. Methodology & Context: ➤ We analyze openness using a standardized framework covering model availability (weights & license) and model transparency (data and methodology). This means we capture not just how freely a model can be used, but visibility into its training and knowledge, and potential to replicate or build on its capabilities or data. ➤ Model availability is measured based on the access and licensing of the model/weights themselves, while transparency comprises subcomponents for access and licensing for methodology, pre-training data, and post-training data. ➤ As seen with releases like DeepSeek R1, sharing methodology accelerates progress. We hope the Index encourages labs to balance competitive moats with the benefits of sharing the "how" alongside the "what." ➤ AI model developers may choose not to fully open their models for a wide range of reasons. We feel strongly that there are important advantages to the open AI ecosystem and supporting the open ecosystem is a key reason we developed the Openness Index. We do not, however, wish to dismiss the legitimacy of the tradeoffs that greater openness comes with, and we do not intend to treat Openness Index as a strictly ‘higher is better’ scale. See below for further analysis and details 👇