@omarsar0
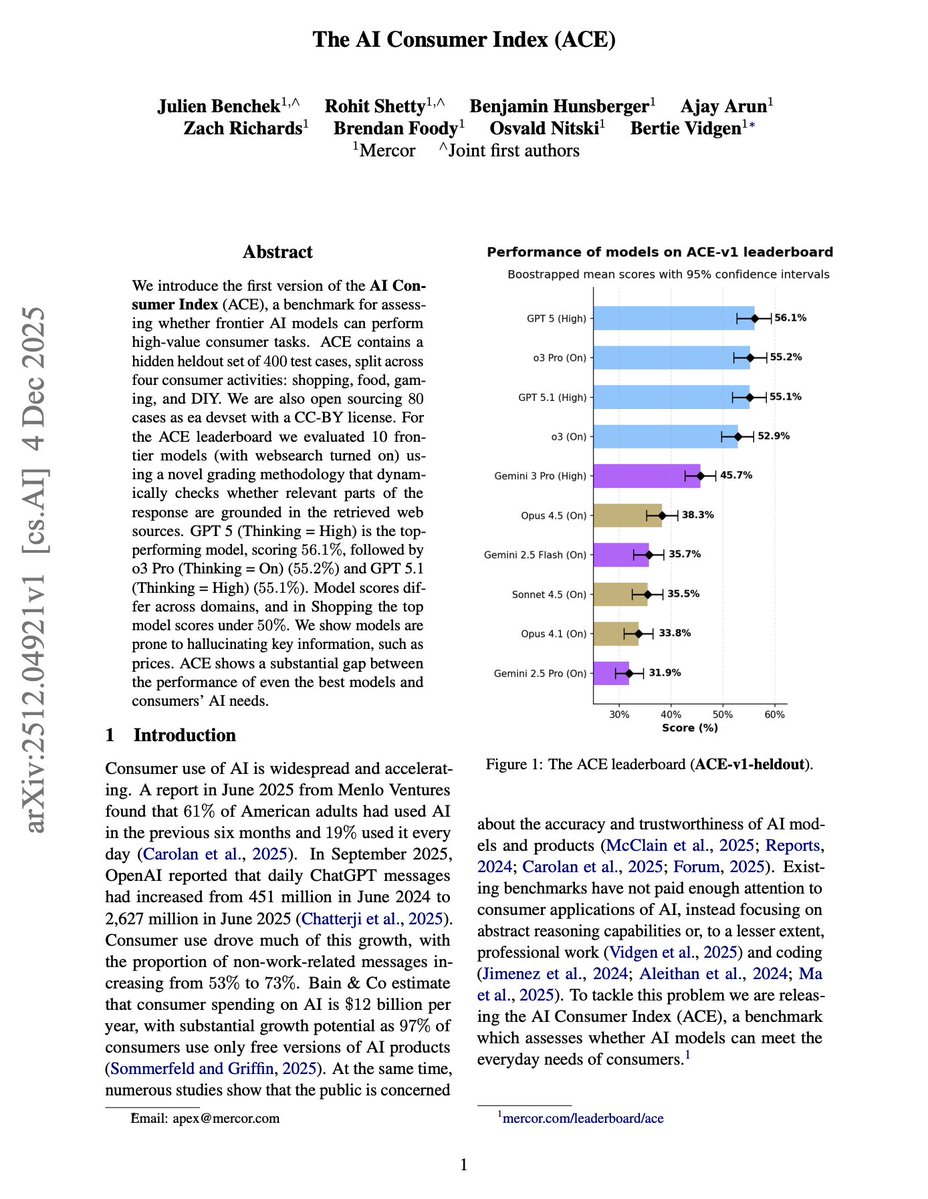
The AI Consumer Index (ACE) Most AI benchmarks today focus on reasoning and coding. But most people use AI to shop, cook, and plan their weekends. In those domains, LLM hallucinations continue to be a real problem. 73% of ChatGPT messages (according a recent report) are now non-work-related. Consumers are using AI for everyday tasks, and we have no systematic way to measure how well models perform on them. This new research introduces ACE (AI Consumer Index), a benchmark assessing whether frontier models can perform high-value consumer tasks across shopping, food, gaming, and DIY. Consumer tasks require grounding in real-world information. A model that hallucinates a product price or provides a dead link isn't just wrong, it's actively unhelpful. ACE's grading methodology dynamically checks whether responses are grounded in retrieved web sources, penalizing hallucinations with negative scores. The results expose a substantial gap: GPT-5 (Thinking = High) leads at 56.1%, followed by o3 Pro at 55.2%. The best model scores only 45.4% on Shopping. Models frequently hallucinate prices and product features, scoring negative on grounded criteria. The study found that on "Provides link(s)" in Shopping, Gemini 3 Pro scores -54%. That's not just failing to provide links, it's confidently providing dead or fabricated ones. Other models like Opus 4.5 also face similar issues. All of these issues can be improved with multi-agent systems, but it's important to be aware of the issue first. The benchmark includes 400 hidden test cases created by 47 domain experts. Each case has fine-grained rubrics distinguishing whether failures come from not meeting requirements versus hallucinating information. Paper: https://t.co/VBSBCJMFHQ ACE reveals the gap between benchmark performance and real-world utility.