@llama_index
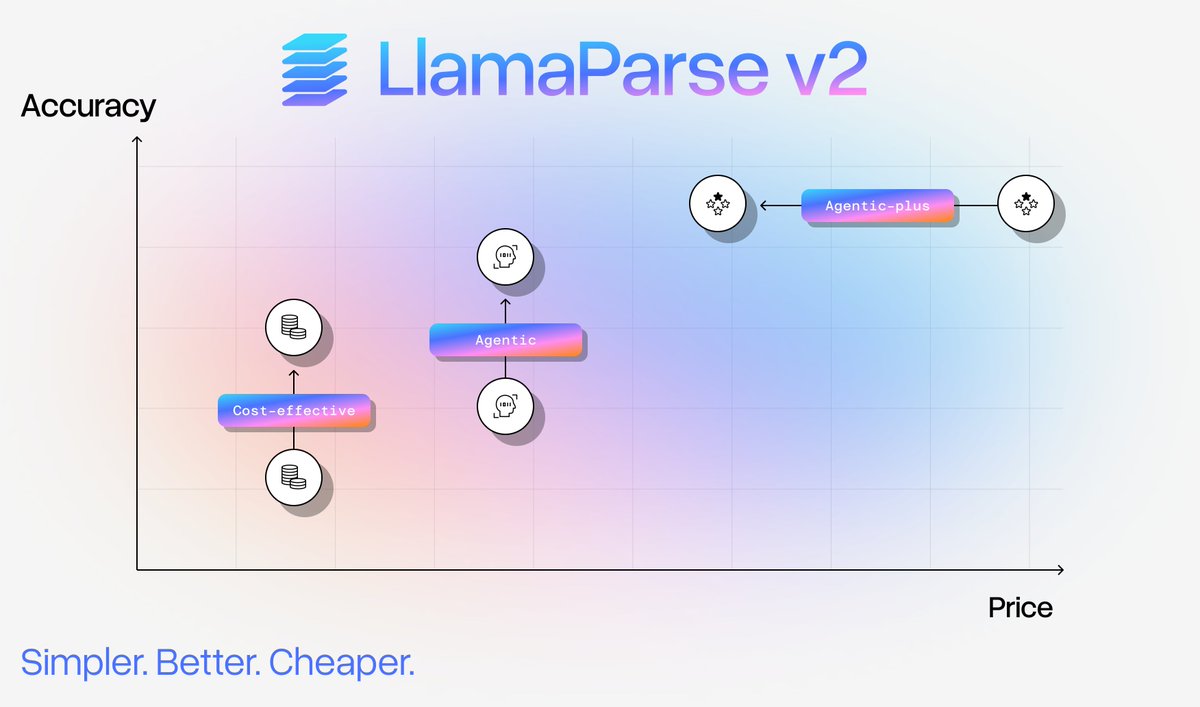
LlamaParse v2 is here: simpler configuration, better performance, and up to 50% cost reduction for document parsing. We'v redesigned our approach based on user feedback to make production-ready document ingestion accessible without becoming a parsing expert. 🚀 Four simple tiers replace complex configuration modes - just pick Fast, Cost Effective, Agentic, or Agentic Plus based on your needs 💰 Significant cost improvements across all tiers, with our Agentic Plus tier offering 50% price reduction ⚡ Enhanced accuracy and reduced hallucinations, especially for complex documents with multimodal content Instead of tuning dozens of parameters and choosing between parsing modes, you now focus on outcomes while we handle the optimal model routing automatically. This means we can ship performance upgrades more frequently without breaking your workflows. Read the full announcement and learn about the new tier system: https://t.co/bsQecEK5mY