@AnthropicAI
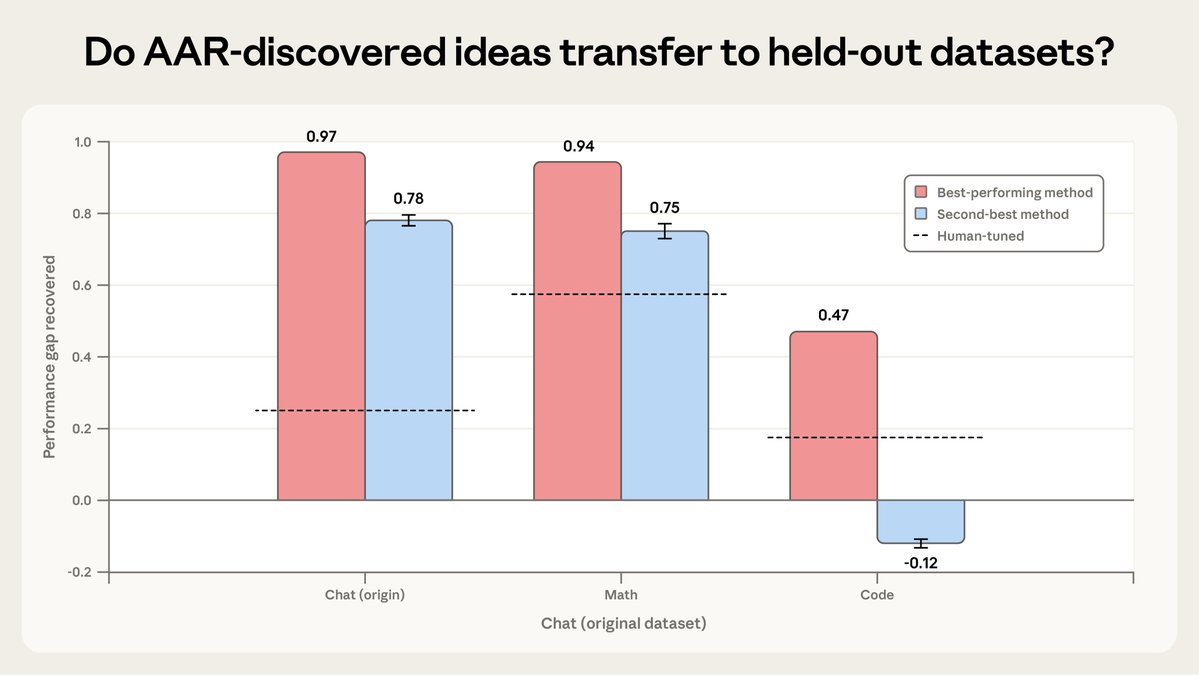
To test the broader usefulness of the AARs’ methods, we assessed how well they worked on two datasets the AARs hadn’t seen before. The AARs’ best-performing method successfully generalized to both coding and math tasks, though their second-best method only generalized to math. https://t.co/r2EUH7MxEK