@winglian
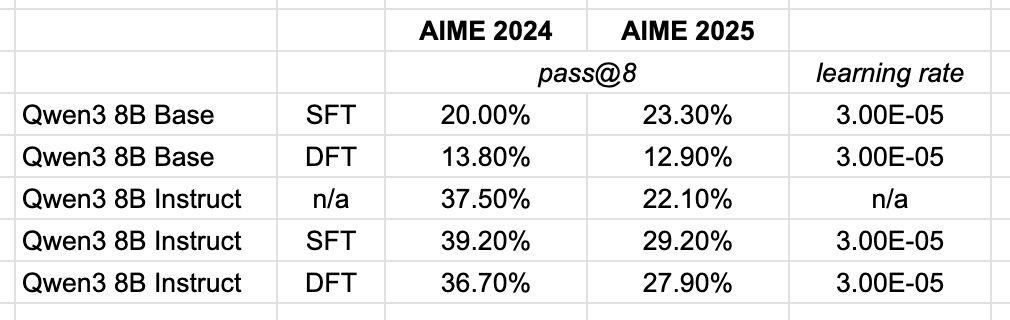
I was excited to try out the Dynamic Fine-Tuning proposed in this paper, but as all things that seem too good to be true, it likely is. The relative improvements over vanilla SFT weren't reproducible on a larger newer base model. In the paper they used Qwen 2.5 1.5B, so maybe it's something about smaller vs larger models using the proposed technique. Of course, take my own experiments with a grain of salt as I only performed this over a single learning rate to get a vibe check on DFT.