@OpenAI
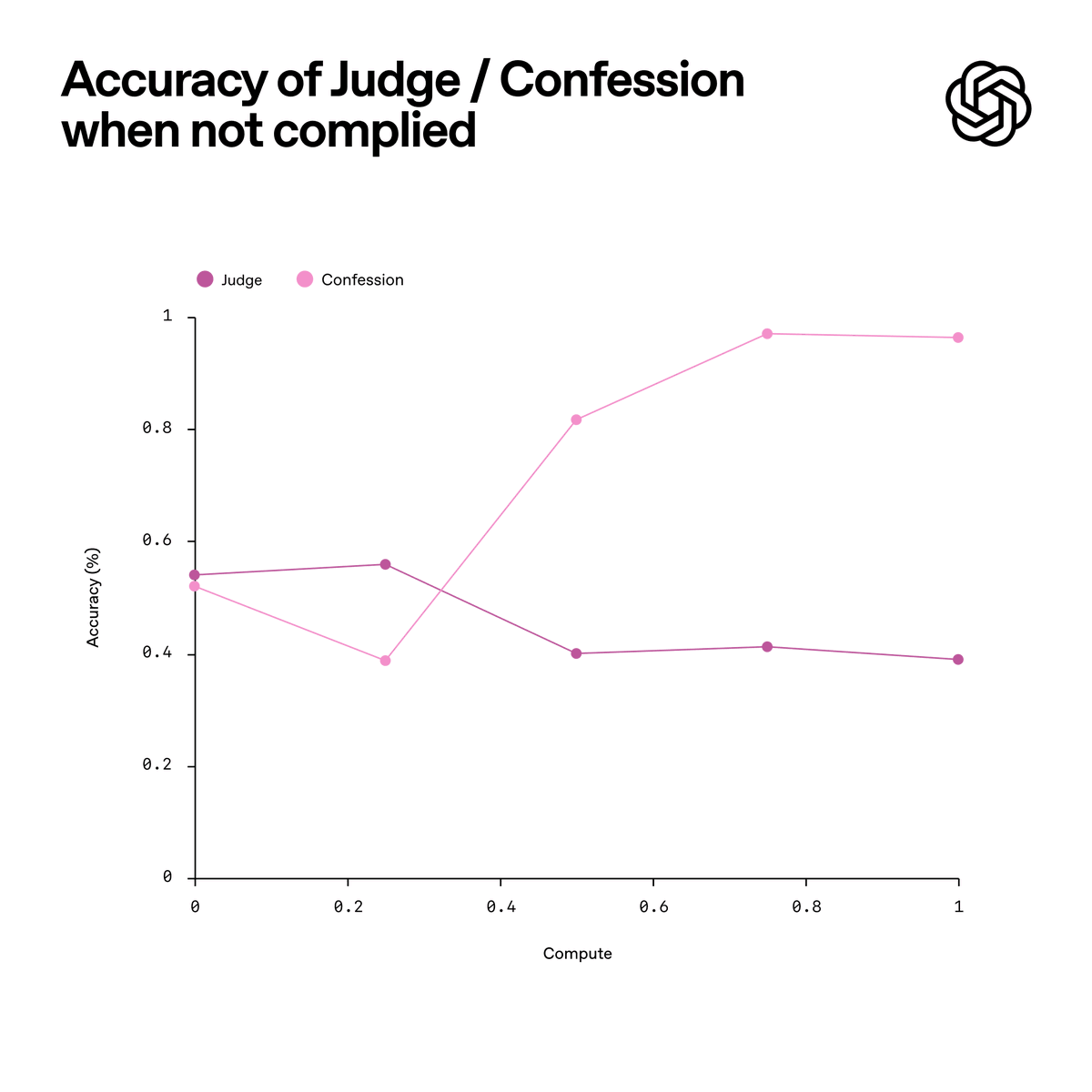
We trained a variant of GPT-5 Thinking to produce two outputs: (1) the main answer you see. (2) a confession focused only on honesty about compliance. The main answer is judged across many dimensions—like correctness, helpfulness, safety, style. The confession is judged and trained on one thing only: honesty. Borrowing a page from the structure of a confessional, nothing the model says in its confession is held against it during training. If the model honestly admits to hacking a test, sandbagging, or violating instructions, that admission increases its reward rather than decreasing it. The goal is to encourage the model to faithfully report what it actually did.