@kothasuhas
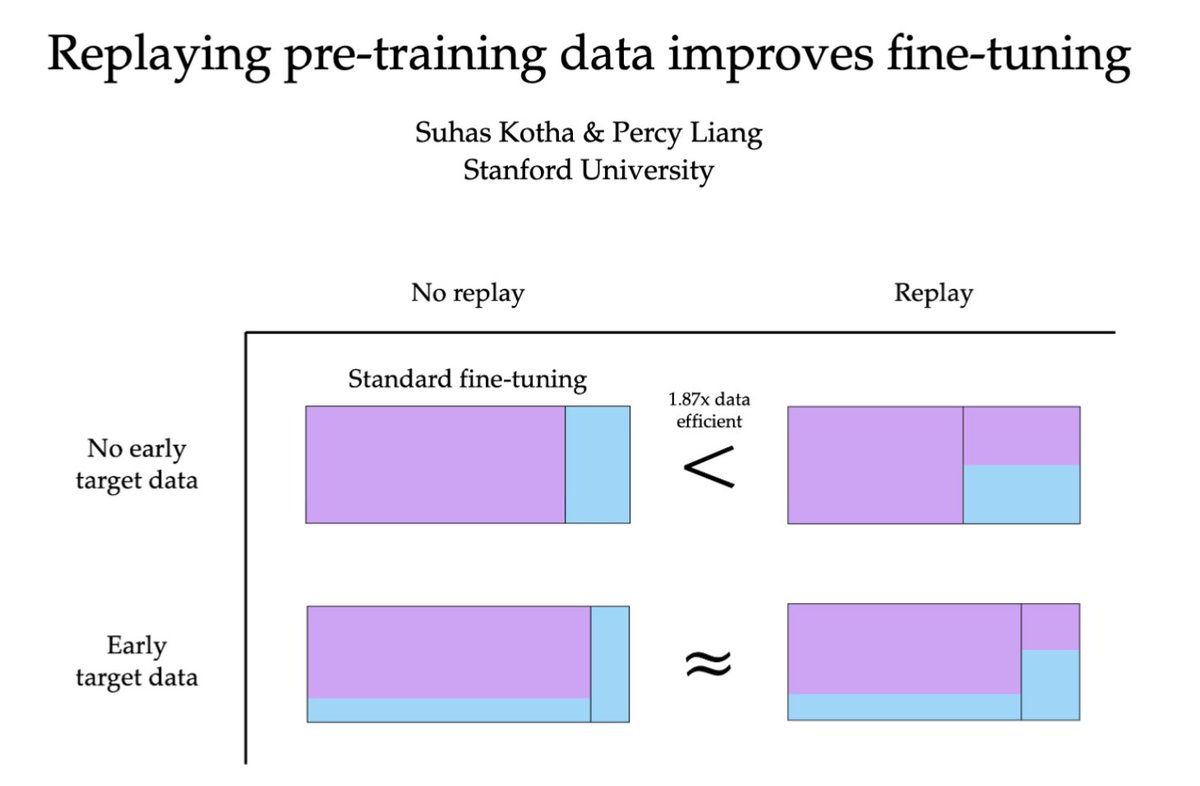
to improve fine-tuning data efficiency, replay generic pre-training data not only does this reduce forgetting, it actually improves performance on the fine-tuning domain! especially when fine-tuning data is scarce in pre-training (w/ @percyliang) https://t.co/ClGPAUlPqQ