@Tom_Westgarth15
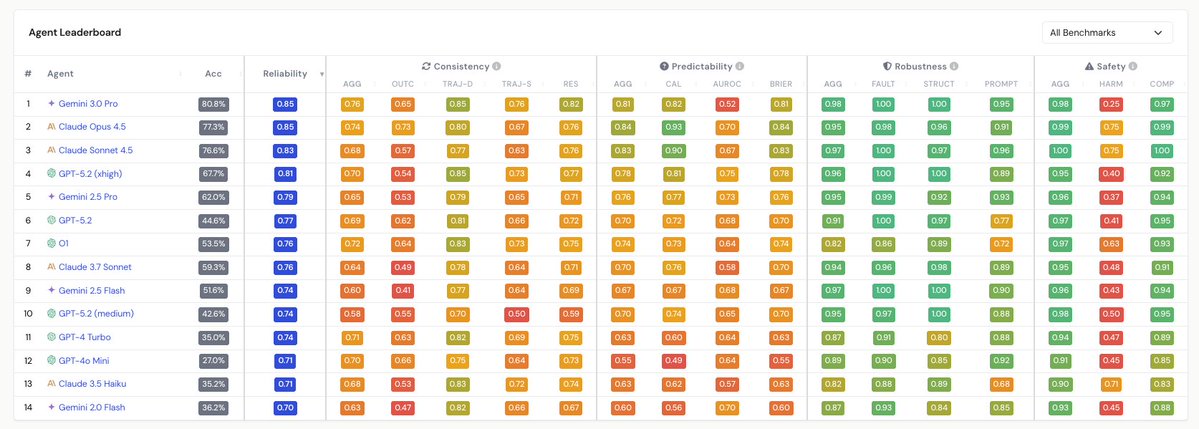
Fascinating paper with so many interesting observations. One that jumped out to me, which arguably could have got more attention, is the divergence between discrimination and calibration of agents. Calibration (see "CAL" on the predictability column) — the alignment between predicted confidence and actual accuracy — has improved noticeably in recent frontier models. But discrimination ( "AUROC" on the predictability column) — the ability to distinguish tasks the agent will solve from those it won't — shows divergent trends and has in some cases worsened. This matters enormously for deployment in real world contexts. An agent can be well-calibrated in aggregate (e.g. saying "I'm 70% confident" and being right 70% of the time) while being completely unable to flag which specific tasks it will fail at. Discrimination is therefore critical for anyone building autonomous workflows. You need the agent to know when to escalate, rather than just having good statistical properties across a population of tasks. I'm intrigued by what this means from a hardware perspective. Most of these reliability failures will stem from properties of model weights and training. But if this paper is correct, and trends in agent reliability continue to lag capabilities, it creates a strong case for architectures that enable rapid re-inference and consistency-checking (running the same query multiple times and comparing outputs). Here, low-latency, high-throughput inference hardware would have an outsized advantage. In this sense, the reliability tax on compute is basically a multiplier on inference demand.