@AlphaSignalAI
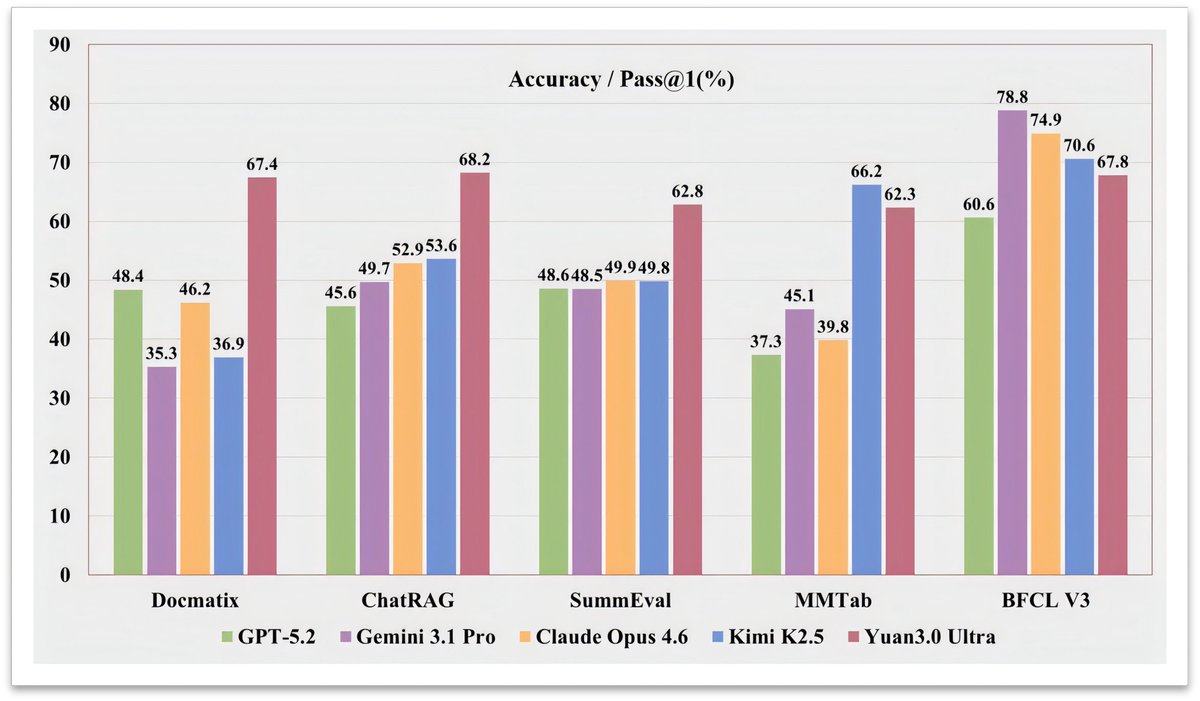
A trillion-parameter model just made half its brain disappear. It got smarter. Yuan3.0 Ultra is a new open-source multimodal MoE model from Yuan Lab. 1010B total parameters, only 68.8B active at inference. It beat GPT-5.2, Gemini 3.1 Pro, and Claude Opus 4.6 on RAG benchmarks by wide margins. 67.4% on Docmatix vs GPT-4o's 56.8%. Here's what it unlocks: > Enterprise RAG with 68.2% avg accuracy across 10 retrieval tasks > Complex table understanding at 62.3% on MMTab > Text-to-SQL generation scoring 83.9% on Spider 1.0 > Multimodal doc analysis with a 64K context window The key innovation: Layer-Adaptive Expert Pruning (LAEP). During pretraining, expert token loads become wildly imbalanced. Some experts get 500x more tokens than others. LAEP prunes the underused ones layer by layer, cutting 33% of parameters while boosting training efficiency by 49%. They also refined "fast-thinking" RL. Correct answers with fewer reasoning steps get rewarded more. This cut output tokens by 14.38% while improving accuracy by 16.33%. The bigger signal here: MoE models are learning to self-compress during training, not after. If pruning becomes part of pretraining, the cost curve for trillion-scale models shifts dramatically.