@namanambavi
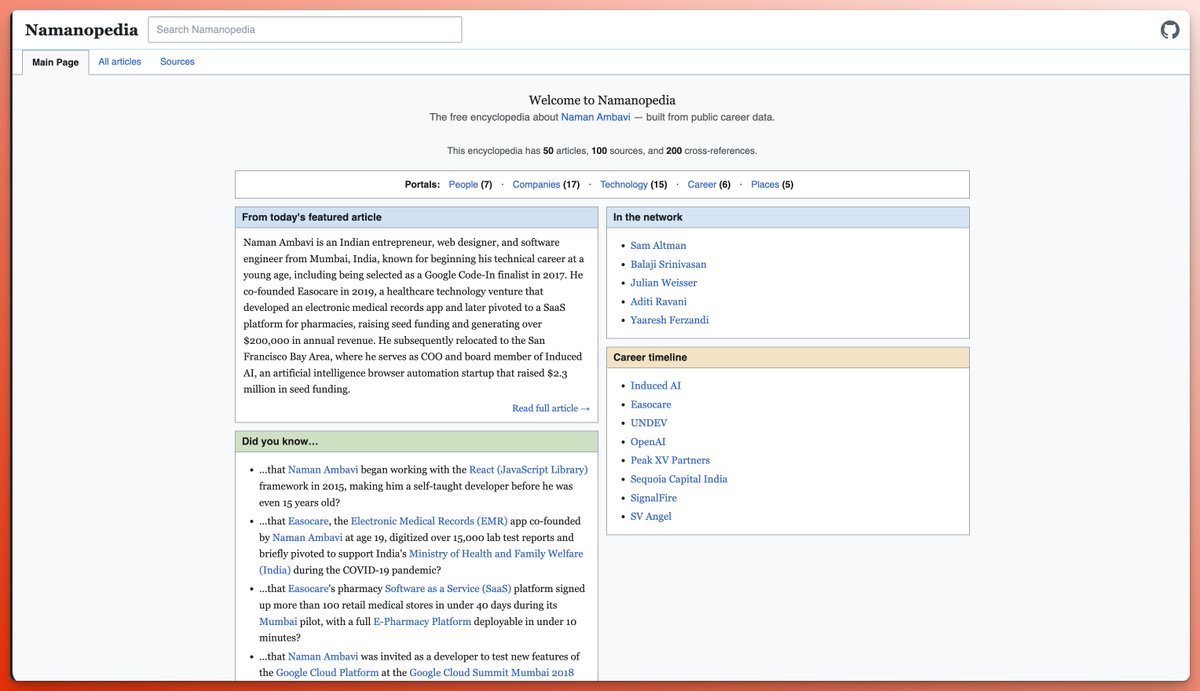
This is Namanopedia. I built lifewiki [https://t.co/3diyla648D]. Paste a name, get their entire Wikipedia. An AI agent researches the web and compiles 40-50+ articles with infoboxes, wikilinks, citations, and categories. Takes about 3 minutes. Inspired by @karpathy's LLM Wiki pattern and @FarzaTV's Farzapedia. Except this one works for anyone, from just a name. https://t.co/gpF4hWrbzQ