@iScienceLuvr
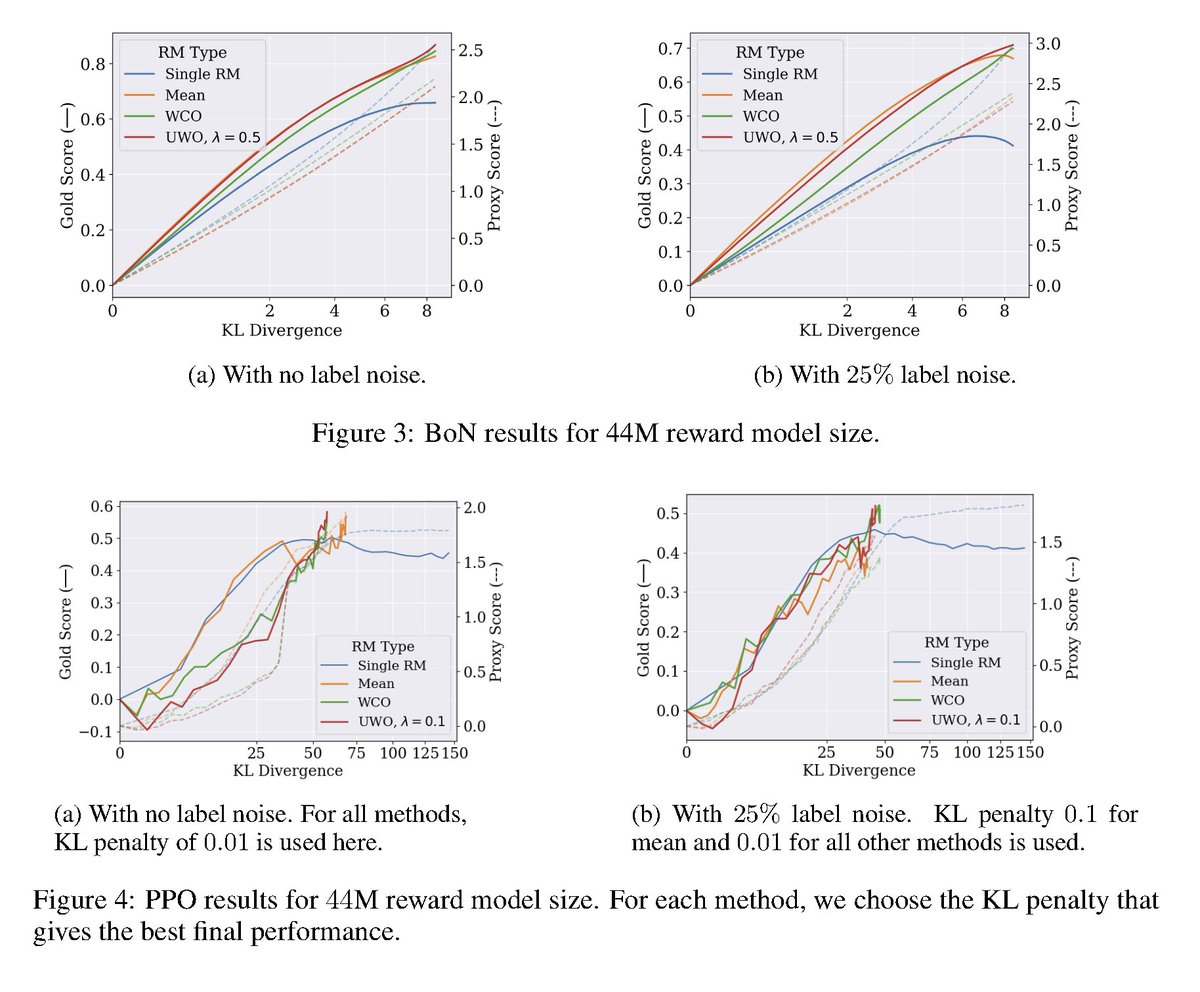
Reward Model Ensembles Help Mitigate Overoptimization abs: https://t.co/JEqdksPnT5 RLHF can struggle with overoptimization, where the policy gets better according to the learned reward model but its true reward is actually worse. Building off Gao et al. 2023, here it is demonstrated that utilizing ensembles of reward models both mitigate overoptimization and also improve overall performance.