@jerryjliu0
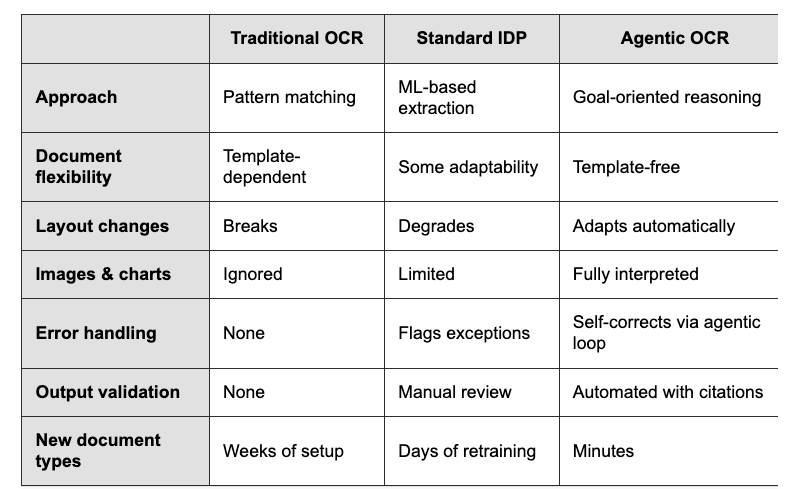
Existing "OCR" technology for digitalizing PDFs has been around for ~30 years. Reading printed characters on a page and converting them into meaningful representations is a hard problem! Existing approaches were either dependent on pattern matching to specific document templates, or on specialized ML models for specific data distributions. They constantly needed template/model refitting and broke on the long-tail of varied docs. Today, vision models are capable of much higher general accuracy without constant retraining, but they still need careful orchestration to make sure that they're able to attend to specific elements (tables, charts), and output semantically correct outputs. Our OCR platform LlamaParse is built on this "agentic OCR" foundation. A network of specialized agents will parse apart even the most complicated documents and reconstruct the outputs in a semantically meaningful way. We're excited to reach a world where raw parsing accuracy is not just 80% over "easy" docs, but 100% accurate over literally any document that exists. Check it out: https://t.co/FeOoTjeKjf LlamaParse: https://t.co/TqP6OT5U5O