@kwindla
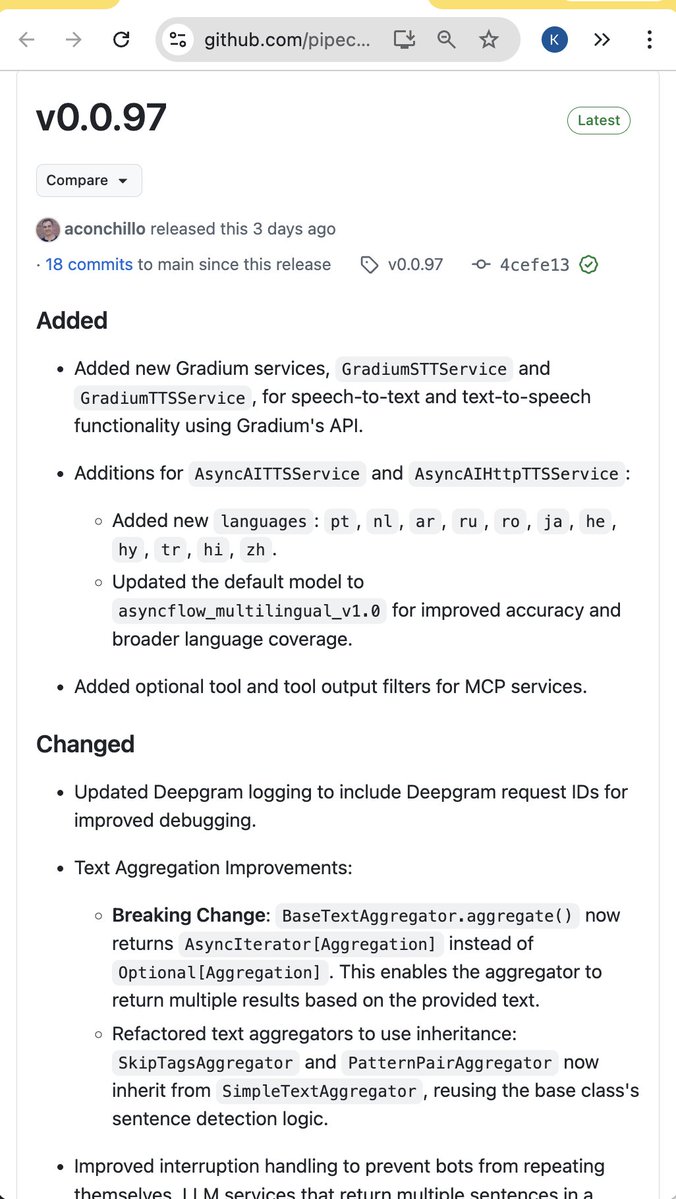
Pipecat 0.0.97 release. Some highlights: Support for @GradiumAI's new speech-to-text and text-to-speech models. Gradium is a voice-focused AI lab that spun out of the non-profit Kyutai Labs, which has been doing architecturally innovative work on neural codecs and speech-language models for the last two years. Continued improvements in the core text aggregator and interruption handling classes, both to fix small corner cases and to make behavior as configurable as possible. This is the kind of often-invisible work that underpins Pipecat's ability to support a wide range of models and pipeline "shapes." Models stream (or don't stream) tokens differently. Different use cases need to make different engineering trade-offs in the service of natural, low-latency interactions. Similarly, continued steps towards full support of reasoning models. Mostly, reasoning models haven't been used in voice AI pipelines, because we are generally prioritizing low latency. But, increasingly, we are using multiple models in parallel in voice agents. Thinking fast and slow, as it were. Using reasoning models requires updating `LLMContext` abstractions to thread thought signatures into the conversation context, and handling function call internals slightly differently. Access to word timestamps from the @cartesia_ai speech-to-text model. The Smart Turn model service now defaults to the new v3.1 weights and uses the full current utterance rather than only the most recent fragment.