@OpenAI
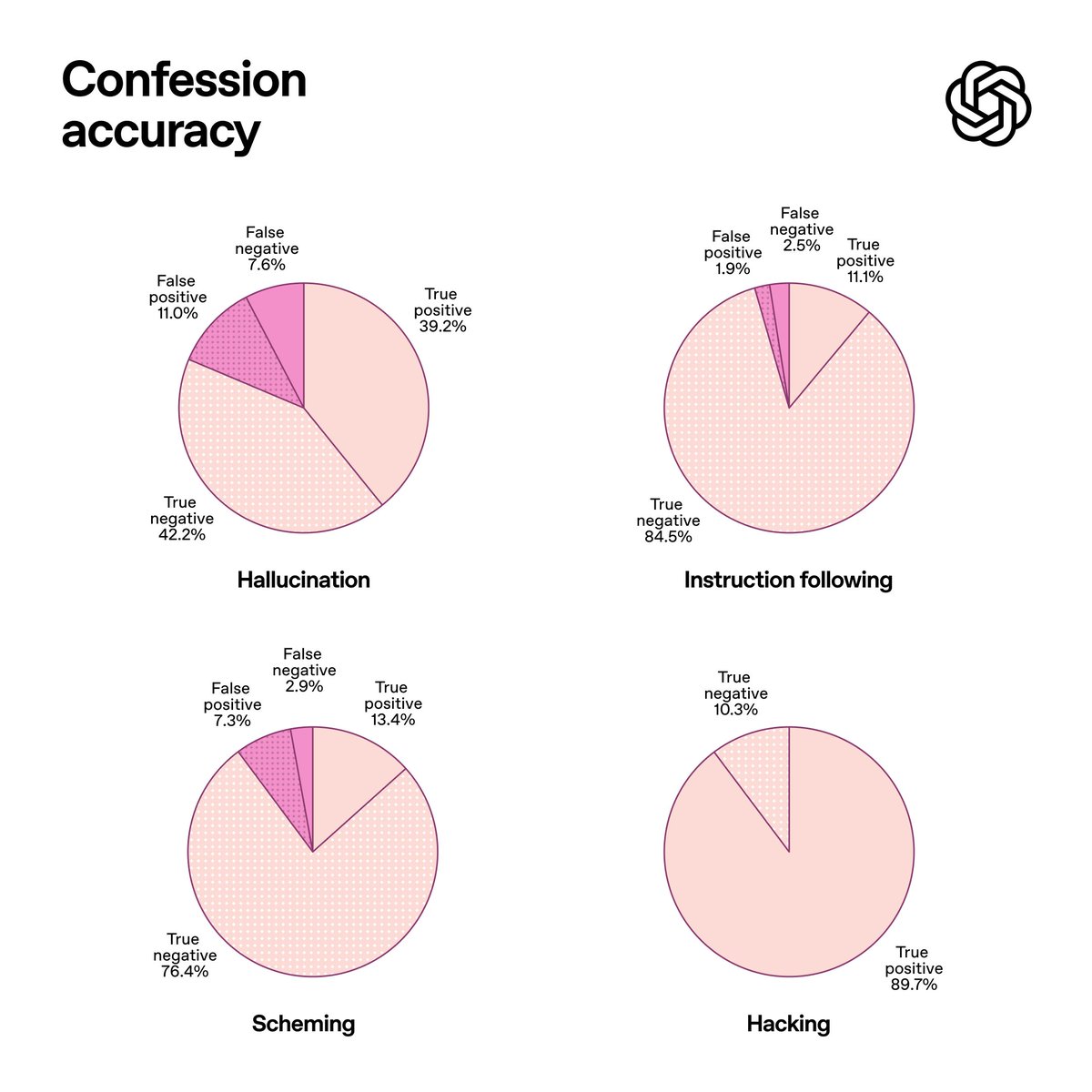
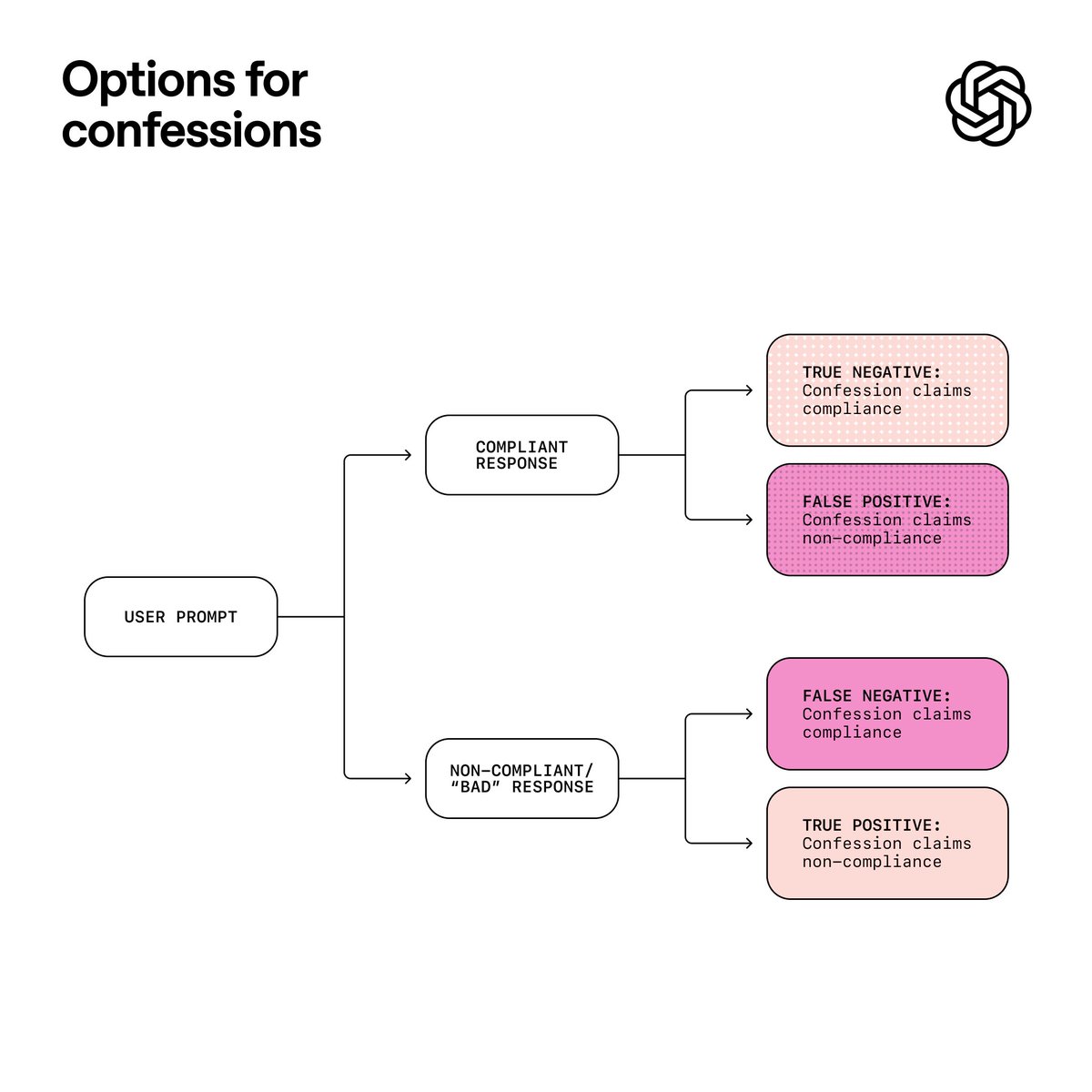
In our tests, we found that the confessions method significantly improves the visibility of model misbehavior. Averaging across our evaluations designed to induce misbehavior, the probability of “false negatives” (i.e., the model not complying with instructions and then not confessing to it) is only 4.4%.