@YIFENGLIU_AI
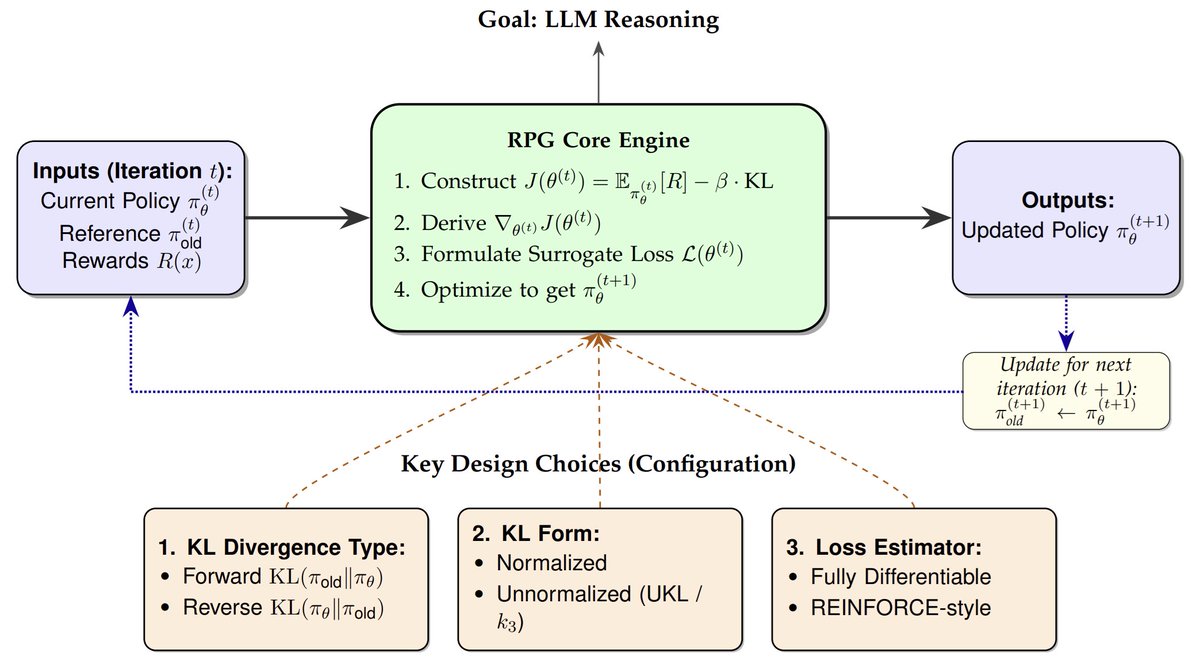
1/6 We introduce RPG, a principled framework for deriving and analyzing KL-regularized policy gradient methods, unifying GRPO/k3-estimator and REINFORCE++ under this framework and discovering better RL objectives than GRPO: Paper: https://t.co/7xSUj01GIx Code:… https://t.co/0pn5sqhhC7