@lqiao
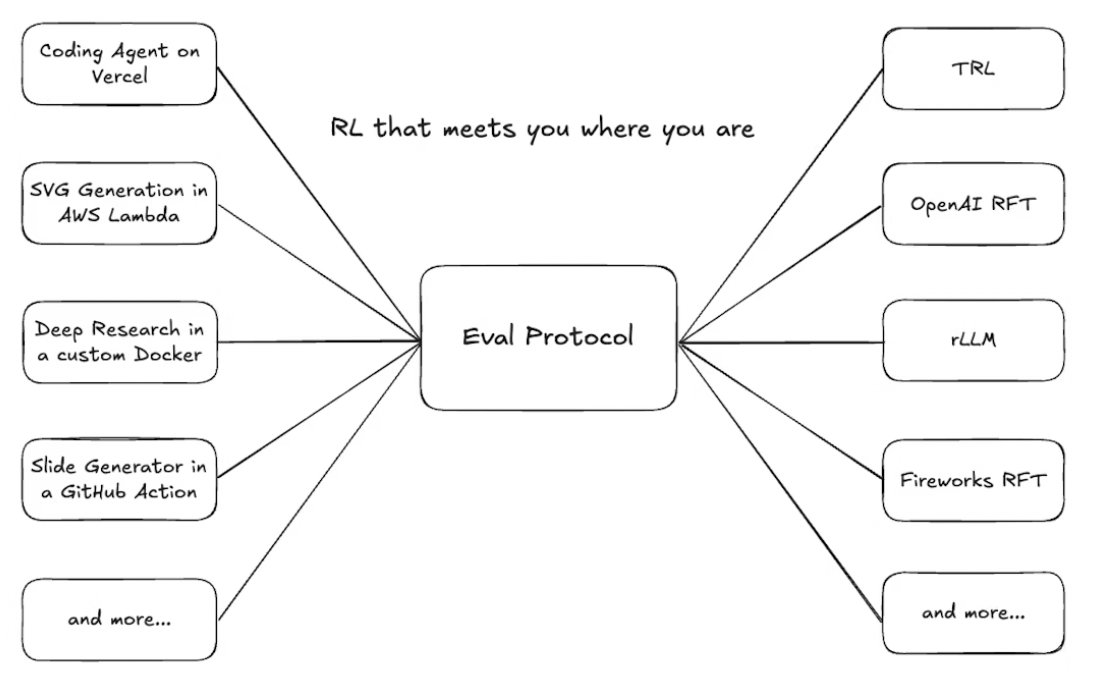
🚀 Eval Protocol is Open Sourced! Reinforcement fine-tuning is complicated, because there are hundreds of environments and tens of trainers you can pick and choose and integrate with. Even worse, in production, agents don’t live in clean “gyms.” They operate in messy, async environments - flaky APIs, partial observability, conflicting objectives, long feedback loops. We solve that problem by open sourcing Eval Protocol. The goal is for you to build your production RFT flow without reinventing the wheel of managing such complex integration. 👉 Day 0 support for trainers and environments like TRL (@huggingface), @rllm_project , OpenEnv (@PyTorch), as well as support for proprietary trainers like @OpenAI RFT and @thinkymachines Tinker. More to come. 👉 Instrument agents in production instead of toy or simulated environments 👉 Move from offline benchmarks to live, continuous improvement