@omarsar0
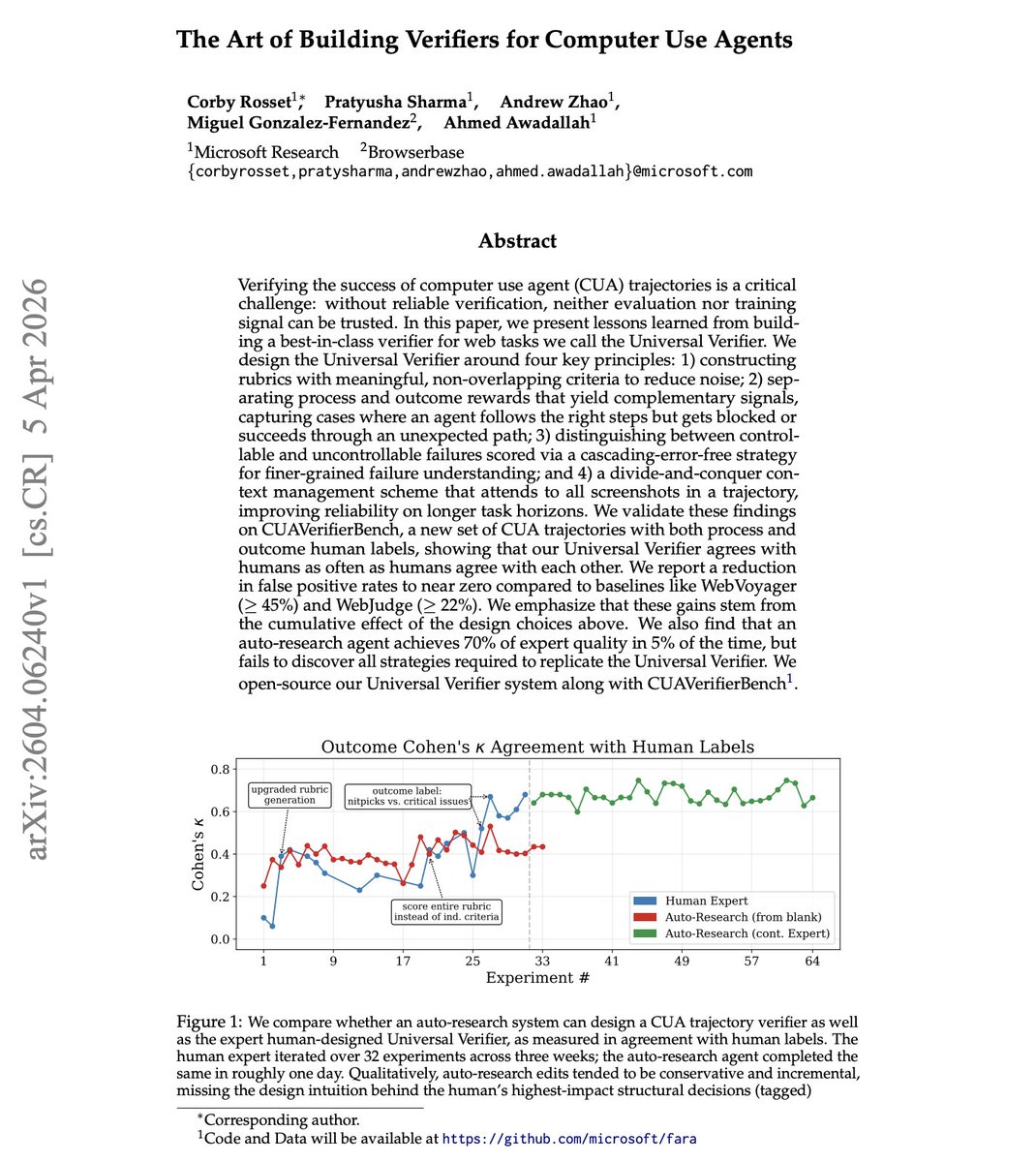
NEW paper from Microsoft Every agent benchmark has the same hidden problem: how do you know the agent actually succeeded? Microsoft researchers introduce the Universal Verifier, which discusses lessons learned from building best-in-class verifiers for web tasks. It's built on four principles: non-overlapping rubrics, separate process vs. outcome rewards, distinguishing controllable from uncontrollable failures, and divide-and-conquer context management across full screenshot trajectories. It reduces false positive rates to near zero, down from 45%+ (WebVoyager) and 22%+ (WebJudge). Without reliable verifiers, both benchmarks and training data are corrupted. One interesting finding is that an auto-research agent reached 70% of expert verifier quality in 5% of the time, but couldn't discover the structural design decisions that drove the biggest gains. Human expertise and automated optimization play complementary roles. Paper: https://t.co/fWhG9I8vPP Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX