@pratyushmaini
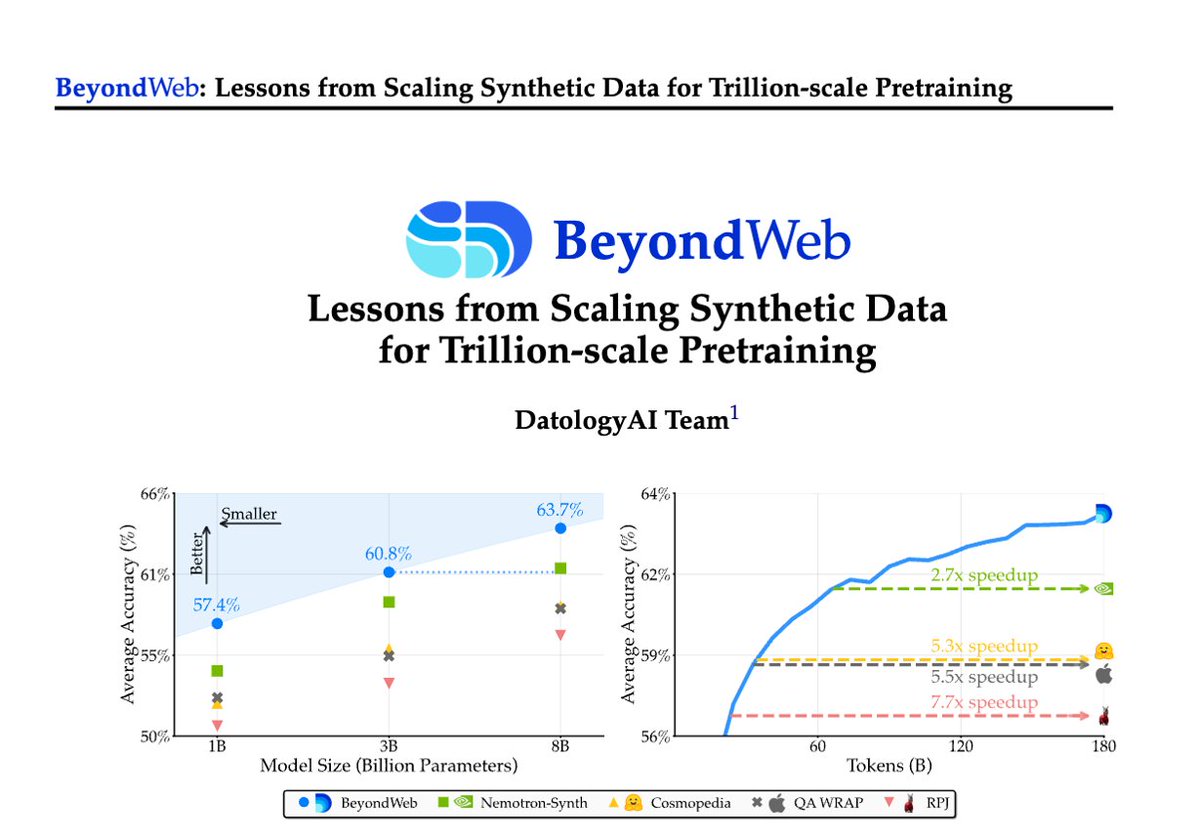
1/Pretraining is hitting a data wall; scaling raw web data alone leads to diminishing returns. Today @datologyai shares BeyondWeb, our synthetic data approach & all the learnings from scaling it to trillions of tokens🧑🏼🍳 - 3B LLMs beat 8B models🚀 - Pareto frontier for performance https://t.co/MUittjMqOO