@llama_index
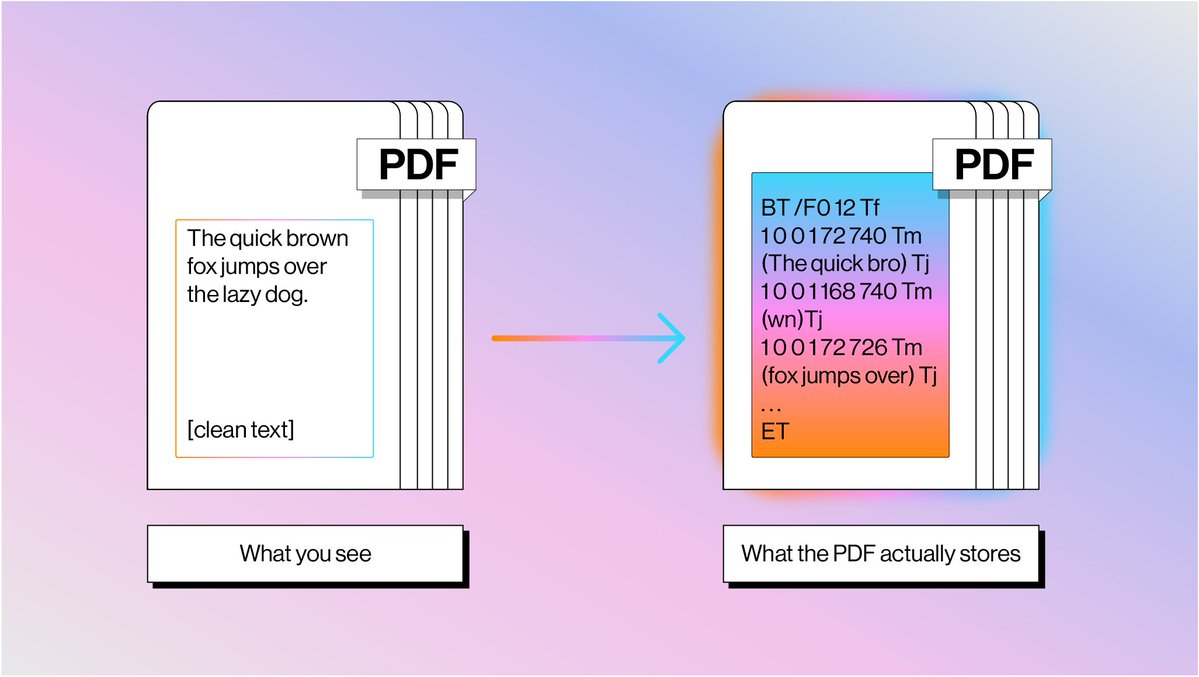
PDFs are the bane of every AI agent's existence: here's why parsing them is so much harder than you think 📄 Every developer building document agents eventually hits the same wall: PDFs weren't designed to be machine-readable. They're drawing instructions from 1982, not structured data. 📝 PDF text isn't stored as characters: it's glyph shapes positioned at coordinates with no semantic meaning 📊 Tables don't exist as objects: they're just lines and text that happen to look tabular when rendered 🔄 Reading order is pure guesswork — content streams have zero relationship to visual flow 🤖 Seventy years of OCR evolution led us to combine text extraction with vision models for optimal results We built LlamaParse using this hybrid approach: fast text extraction for standard content, vision models for complex layouts. It's how we're solving document processing at scale. Read the full breakdown of why PDFs are so challenging and how we're tackling it: https://t.co/K8bQmgq7xN