@omarsar0
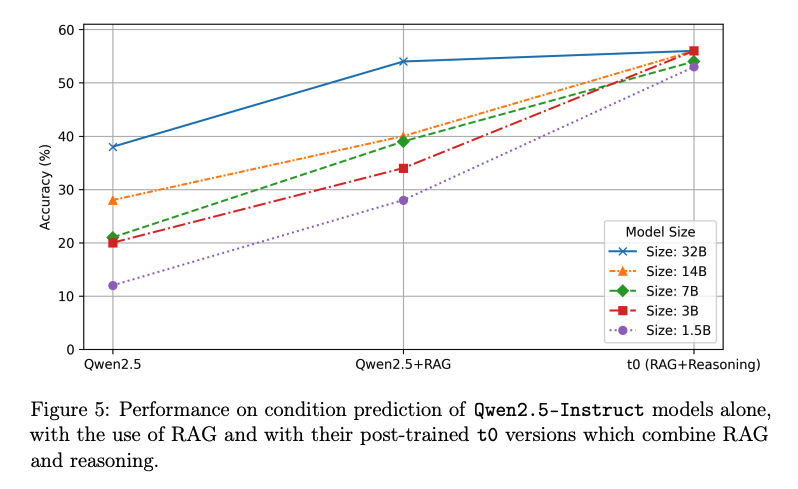
Small models, big gains. Distilled “t0” models from 1.5B–32B retain strong condition accuracy with k=5 (e.g., 1.5B at 0.53; 32B at 0.56), narrowing the gap to frontier models while fitting in 3–64 GB GPU memory. The study highlights that reasoning distillation especially lifts the smallest models.