@AlphaSignalAI
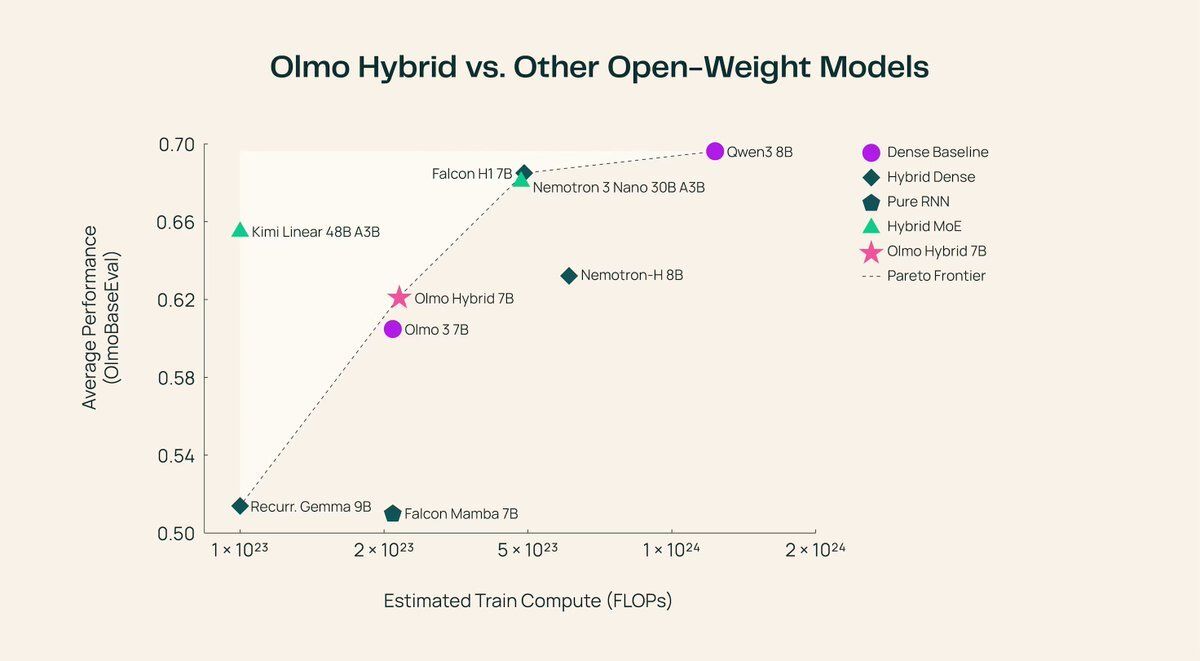
Transformers just got a serious rival. Allen AI just open-sourced a 7B model that beats its own transformer. OLMo Hybrid mixes standard attention with linear RNN layers into one architecture. > Same accuracy, half the training data > Long-context jumps from 70.9% to 85.0% > Beats the pure transformer on every eval domain > Fully open: base, fine-tuned, and aligned versions The trick is a 3:1 pattern. Three recurrent layers handle most of the sequence processing cheaply. One attention layer then catches what the recurrent state missed. This cuts 75% of the expensive attention operations while keeping precision where it matters. Building long-context apps used to mean paying the full cost of attention across every layer. Now you can get better long-context performance with a leaner architecture, and the theory proving why it scales better is released alongside the weights. https://t.co/bxZ7ckAOq4