@_avichawla
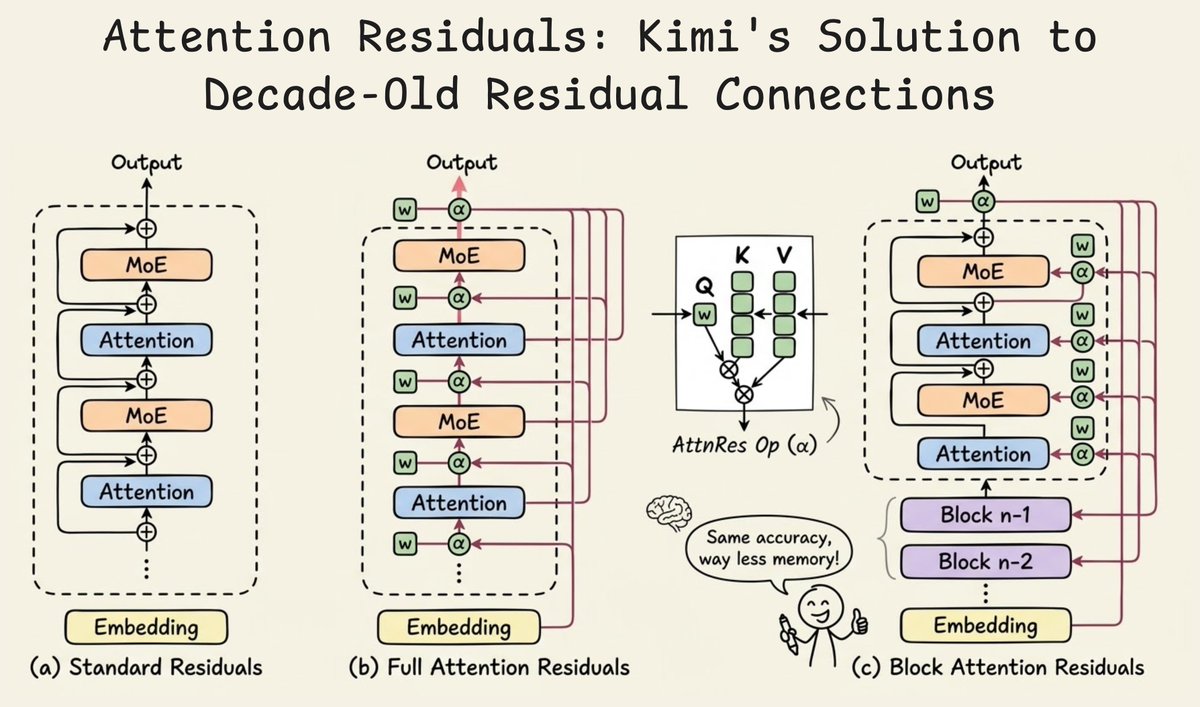
Big release from Kimi! They just released a new way to handle residual connections in Transformers. In a standard Transformer, every sub-layer (attention or MLP) computes an output and adds it back to the input via a residual connection. If you consider this across 40+ layers, the hidden state at any layer is just the equal-weighted sum of all previous layer outputs. Every layer contributes with weight=1, so every layer gets equal importance. This creates a problem called PreNorm dilution, where as the hidden state accumulates layer after layer, its magnitude grows linearly with depth. And any new layer's contribution gets progressively buried in the already-massive residual. This means deeper layers are then forced to produce increasingly large outputs just to have any influence, which destabilizes training. Here's what the Kimi team observed and did: RNNs compress all prior token information into a single state across time, leading to problems with handling long-range dependencies. And residual connections compress all prior layer information into a single state across depth. Transformers solved the first problem by replacing recurrence with attention. This was applied along the sequence dimension. Now they introduced Attention Residuals, which applies a similar idea to depth. Instead of adding all previous layer outputs with a fixed weight of 1, each layer now uses softmax attention to selectively decide how much weight each previous layer's output should receive. So each layer gets a single learned query vector, and it attends over all previous layer outputs to compute a weighted combination. The weights are input-dependent, so different tokens can retrieve different layer representations based on what's actually useful. This is Full Attention Residuals (shown in the second diagram below). But here's the practical problem with this idea. Full AttnRes requires keeping all layer outputs in memory and communicating them across pipeline stages during distributed training. To solve this, they introduce Block Attention Residuals (shown in the third diagram below). The idea is to group consecutive layers into roughly 8 blocks. Within each block, layer outputs are summed via standard residuals. But across blocks, the attention mechanism selectively combines block-level representations. This drops memory from O(Ld) to O(Nd), where N is the number of blocks. Layers within the current block can also attend to the partial sum of what's been computed so far inside that block, so local information flow isn't lost. And the raw token embedding is always available as a separate source, which means any layer in the network can selectively reach back to the original input. Results from the paper: - Block AttnRes matches the loss of a baseline LLM trained with 1.25x more compute. - Inference latency overhead is less than 2%, making it a practical drop-in replacement - On a 48B parameter Kimi Linear model (3B activated) trained on 1.4T tokens, it improved every benchmark they tested: GPQA-Diamond +7.5, Math +3.6, HumanEval +3.1, MMLU +1.1 The residual connection has mostly been unchanged since ResNet in 2015. This might be the first modification that's both theoretically motivated and practically deployable at scale with negligible overhead. More details in the post below by Kimi👇 ____ Find me → @_avichawla Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.